
Understanding the Evolution of ChatGPT: Part 3— Insights from Codex and InstructGPT
Mastering the art of fine-tuning: Learnings for training your own LLMs.(Image from Unsplash)This is the third article in our GPT series, and also the most practical one: finally, we will talk about how to effectively fine-tune LLMs.It is practical in the way that, if you were asked to train your own LLMs today, you can skip pre-training and jump straight into using an open-source LLM or SLM; However, very likely you’ll still need to finetune it a bit on your own data and task, and that is where this article can come to help.More specifically, we will focus on two finetuned models — Codex and InstructGPT, as they represent addressing two types of challenges in LLM finetuning:Codex needs to adapt a pretrained LLM to a different modality (code script), as programming languages have many unique characteristics than natural language;InstructGPT aims to make the model more aligned with human preferences, which cannot be achieved automatically by traditional language modeling objectives.As we will see later, both challenges demand creativity and carefulness at every stage of the finetuning process: how to collect high-quality data, how to modify model architectures, how to effectively initialize your model, how to determine a proper objective, and how to properly evaluate it.Below is the outline for this article:Overview: why we need finetuning and what makes it so challenging; GPT3.5 and its finetuned versions.Codex: how to evaluate code generation properly, how to collect data and how to adapt the model to process programming languages.InstructGPT and ChatGPT: how to evaluate alignment, why RLHF works, and how it is implemented in InstructGPT.Summary: best practices in LLM finetuning.Below are the links to our previous articles if you are interested:Part 1: An In-Depth Look at GPT-1 and What Inspired It: where we cover the pre-training plus finetuning paradigm and its evolution from CV to NLP, previous pre-training efforts such as Word2Vec and GloVe, decoder-only Transformers, auto-regressive vs. auto-encoding LM, and key innovations of GPT-1.Part 2: GPT-2 and GPT-3: where we cover how GPT models were scaled up from 117M to 175B, under the philosophy of exploring task-agnostic pre-training via scaling hypothesis and in-context learning.OverviewAs we explained in our second article, both GPT-2 and GPT-3 can be considered as OpenAI’s experiments to test the potential of task-agnostic pre-training. While doing so, the authors also mentioned finetuning as a promising direction for future studies, as it might help the model to further improve its performance on certain tasks.Why is Finetuning Needed?The reasons are three-fold.The first reason is of course performance. Pre-trained models are more like generalists that can perform a wide range of tasks reasonably well, but still they might struggle to beat the specialists trained on a particular task. If our goal is to have such a specialized model to help us on a very specific task, then finetuning should be definitely considered.Another reason is that, albeit being generally powerful, GPT-3 models are not always reliable in following human instructions, especially when those instructions became complex. This is because, as the authors explained in InstructGPT paper, that the pre-training objective focuses mainly on language modeling like predicting the next token, but such capabilities cannot translates to instruction-following. Thus, some special finetuning strategies are needed.There are also concerns on safety and ethical aspects, due to very similar reasons that auto-regressive language modeling alone is not sufficient to enforce the model to avoid generating harmful or biased answers. For that issue, finetuning can also enable us to better control the generation process.Challenges in FinetuningBroadly speaking, there are two types of challenges in finetuning LLMs: the need to adapt to a new modality, and the need to align the model with human preferences.Taking Codex as an example for the former case, where the pre-trained model needs to be applied to a different modality that presents some unique characteristics, for example, to process code scripts it needs to understand basic syntax of a specific programming language, handle static and dynamic types and even infer types, and correctly handle indentations in languages like Python.The latter case is more tricky in some way, as “alignment” itself is a pretty vague and controversial concept, and it has to be defined more clearly and translated to a set of measurable aspects before we can actually finetuning towards that goal. Moreover, even if we have worked out a definition of alignment, achieving that goal is also non-trivial, as there is no ready-to-use training objectives directly connect to it.On top of that, we also need to collect high-quality domain-specific training data and rethink the evaluation process, including the evaluation dataset as well as the evaluation metrics to use.In later sections, we wil
 Editor-Admin
Editor-Admin

Mastering the art of fine-tuning: Learnings for training your own LLMs.

This is the third article in our GPT series, and also the most practical one: finally, we will talk about how to effectively fine-tune LLMs.
It is practical in the way that, if you were asked to train your own LLMs today, you can skip pre-training and jump straight into using an open-source LLM or SLM; However, very likely you’ll still need to finetune it a bit on your own data and task, and that is where this article can come to help.
More specifically, we will focus on two finetuned models — Codex and InstructGPT, as they represent addressing two types of challenges in LLM finetuning:
- Codex needs to adapt a pretrained LLM to a different modality (code script), as programming languages have many unique characteristics than natural language;
- InstructGPT aims to make the model more aligned with human preferences, which cannot be achieved automatically by traditional language modeling objectives.
As we will see later, both challenges demand creativity and carefulness at every stage of the finetuning process: how to collect high-quality data, how to modify model architectures, how to effectively initialize your model, how to determine a proper objective, and how to properly evaluate it.
Below is the outline for this article:
- Overview: why we need finetuning and what makes it so challenging; GPT3.5 and its finetuned versions.
- Codex: how to evaluate code generation properly, how to collect data and how to adapt the model to process programming languages.
- InstructGPT and ChatGPT: how to evaluate alignment, why RLHF works, and how it is implemented in InstructGPT.
- Summary: best practices in LLM finetuning.
Below are the links to our previous articles if you are interested:
- Part 1: An In-Depth Look at GPT-1 and What Inspired It: where we cover the pre-training plus finetuning paradigm and its evolution from CV to NLP, previous pre-training efforts such as Word2Vec and GloVe, decoder-only Transformers, auto-regressive vs. auto-encoding LM, and key innovations of GPT-1.
- Part 2: GPT-2 and GPT-3: where we cover how GPT models were scaled up from 117M to 175B, under the philosophy of exploring task-agnostic pre-training via scaling hypothesis and in-context learning.
Overview
As we explained in our second article, both GPT-2 and GPT-3 can be considered as OpenAI’s experiments to test the potential of task-agnostic pre-training. While doing so, the authors also mentioned finetuning as a promising direction for future studies, as it might help the model to further improve its performance on certain tasks.
Why is Finetuning Needed?
The reasons are three-fold.
The first reason is of course performance. Pre-trained models are more like generalists that can perform a wide range of tasks reasonably well, but still they might struggle to beat the specialists trained on a particular task. If our goal is to have such a specialized model to help us on a very specific task, then finetuning should be definitely considered.
Another reason is that, albeit being generally powerful, GPT-3 models are not always reliable in following human instructions, especially when those instructions became complex. This is because, as the authors explained in InstructGPT paper, that the pre-training objective focuses mainly on language modeling like predicting the next token, but such capabilities cannot translates to instruction-following. Thus, some special finetuning strategies are needed.
There are also concerns on safety and ethical aspects, due to very similar reasons that auto-regressive language modeling alone is not sufficient to enforce the model to avoid generating harmful or biased answers. For that issue, finetuning can also enable us to better control the generation process.
Challenges in Finetuning
Broadly speaking, there are two types of challenges in finetuning LLMs: the need to adapt to a new modality, and the need to align the model with human preferences.
Taking Codex as an example for the former case, where the pre-trained model needs to be applied to a different modality that presents some unique characteristics, for example, to process code scripts it needs to understand basic syntax of a specific programming language, handle static and dynamic types and even infer types, and correctly handle indentations in languages like Python.
The latter case is more tricky in some way, as “alignment” itself is a pretty vague and controversial concept, and it has to be defined more clearly and translated to a set of measurable aspects before we can actually finetuning towards that goal. Moreover, even if we have worked out a definition of alignment, achieving that goal is also non-trivial, as there is no ready-to-use training objectives directly connect to it.
On top of that, we also need to collect high-quality domain-specific training data and rethink the evaluation process, including the evaluation dataset as well as the evaluation metrics to use.
In later sections, we will see how Codex and InstructGPT handled these issues. In particular, we will highlight how they implemented every step with both creativity and carefulness, from which anyone who wants to finetune his or her own LLM can learn something.
GPT-3.5
GPT-3.5 series typically refer to the model series finetuned on top of GPT-3, including the following variants (see wiki):
- code-davinvi-002: a version of Codex.
- text-davinci-002: a transitional model from GPT-3 to InstructGPT.
- text-davinci-003: more similar to InstructGPT.
Overall, GPT-3.5 could be considered as finetuned GPT-3 with enhanced instruction following, better generation quality, and better steerability. It is the foundation to several other models including ChatGPT, Codex, Whisper and the text model of DALL-E2, which demonstrates the potential of effectively finetuning LLMs on specialized tasks.
In the following sections, we will dive deeper into Codex and InstructGPT. Rather than covering every detail of their finetuning process, we will mainly focus on the aspects that best showcase the importance of creativity and carefulness.
Codex
The Codex model was released in 2021 and is specialized in Python code-writing.
Below are a few aspects that we want to highlight.
Evaluation of Code Generation
When building a model for a new task, the first thing that often comes to mind is how to evaluate that task properly.
This is important because, without an effective evaluation protocol, we cannot determine if we are really making any progress, and sometimes we even cannot identify the gaps in our current model in the first place.
In the case of Codex, the authors first realized that standard match-based metrics such as BLEU score are not suitable for measuring code generation performance.
In case you are not familiar with BLEU score: it is widely used for evaluating text generation tasks such as machine translation, by comparing overlapping phrases and calculating a precision score, while also considering text length to ensure balance.
However, the same coding problem might be solved with different data structures or algorithms. For example, generating a Fibonacci sequence can be implemented by either a top-down or bottom-up DP algorithm, resulting in very different code scripts:
def fib_top_down(n, memo={}):
if n in memo:
return memo[n]
if n <= 1:
return n
memo[n] = fib_top_down(n-1, memo) + fib_top_down(n-2, memo)
return memo[n]
def fib_bottom_up(n):
if n <= 1:
return n
dp = [0] * (n + 1)
dp[0], dp[1] = 0, 1
for i in range(2, n + 1):
dp[i] = dp[i-1] + dp[i-2]
return dp[n]In that case, if we evaluate both solutions against a given reference solution using BLEU score, it is very likely that one or even both solutions will have very low BLEU scores, even though both solutions are correct.
An alternative way is to evaluate by what the authors called “functional correctness”, for example the pass@k metric used by Kulal et al, where for each problem we will generate k code samples and test each of them, and then a problem can be considered as solved if any sample passes the unit tests. In the end, the total fraction of problems solved is reported. However, as the authors pointed out, calculating pass@k with this definition will result in high variance due to randomness in this process, especially when k is small.
To mitigate this issue, the authors propose another way to estimate pass@k: instead of generating k samples directly, they generate n ≥ k samples per task. As more samples are generated and tested, the estimation process will be more reliable even if k is small. And then, based on how many samples are correct (assume c samples passes unit tests), an unbiased estimator can be estimated as below:
where
- C(n, k) is the number of ways to choose k samples out of n;
- C(n-c, k) is the number of ways to choose k samples out of the (n-c) incorrect samples;
- Thus, C(n-c, k)/C(n, k) represents the probability that all chosen samples are incorrect;
- Finally, 1 — C(n-c, k)/C(n, k) represents the probability that at least one sample is correct.
To further prove that optimizing for BLEU score is not equivalent to optimizing for functional correctness, the authors also plot the BLEU score densities for correct (blue) and wrong (green) solutions for 4 random coding problems, where the distributions are clearly not separable: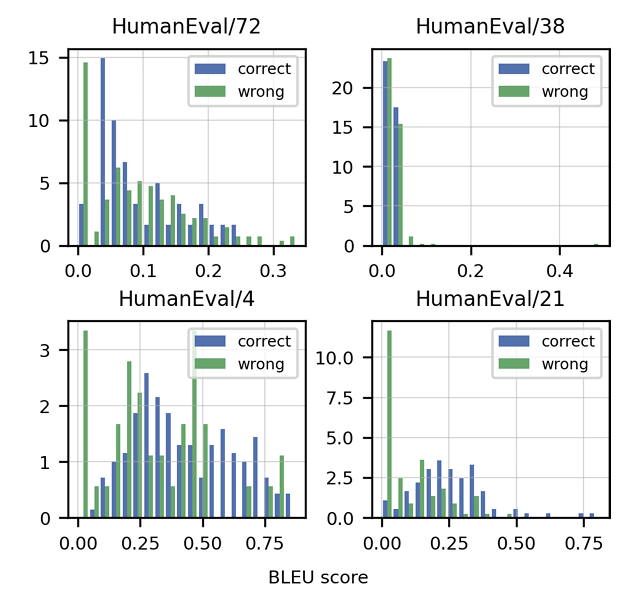
Beyond optimizing for the evaluation metric, the authors also built a new dataset called HumanEval, which contains 164 hand-written programming problems. As shown in the example below, each problem includes a function signature, a docstring, a body and an average of 7.7 unit tests:
Note that as the authors mentioned in the paper, it is important for these tasks to be hand-written, since otherwise the problems for evaluation might be overlap with that for training. Also, to ensure the testing process will not pose any risks due to malicious code, the authors also created a sandbox to execute code scripts.
Training Data Collection
Moving to the training part, the first question is how to collect high-quality training data. For code generation, the good news is that we can leverage the vast amount of code repositories from GitHub, but still some data cleaning strategies are needed, as the paper mentioned:
We filtered out files which were likely auto-generated, had average line length greater than 100, had maximum line length greater than 1000, or contained a small percentage of alphanumeric characters.
Note that most of these cleaning strategies are specialized to programming languages, so we might need to come up with other ideas when cleaning our own data.
Adaptations in Finetuning
The most important adaptation is for the tokenizer, due to the obvious reason that the distribution of words in GitHub code differs a lot from that of natural language. In the Codex paper, the authors noted that this is especially the case when encoding whitespaces, making the original GPT-3 tokenizer less effective.
To fix that issue, an additional set of tokens were added to the vocabulary, to represent whitespace runs of different lengths. As mentioned in the paper, this simple modification enables representing code with 30% fewer tokens.
So, if our model needs to handle an input corpus presents different distribution with natural languages, we might need to do some study on the distribution and modify the tokenizer a bit as well.
Findings in Evaluation
Firstly, the figure below shows the pass rates of different models on the HumanEval dataset. Overall, all the Codex variants show significantly better performance compared to GPT-3, where
- Codex (finetuned on code) solves 28% of the problems;
- Codex-S (finetuned on standalone functions) solves 37.7%;
- Codex-S with generating 100 samples and selecting the one with the highest mean log-probability solves 44.5%;
- Codex-S oracle which selects the sample that passes the unit tests solves an amazing of of 77.5% problems.
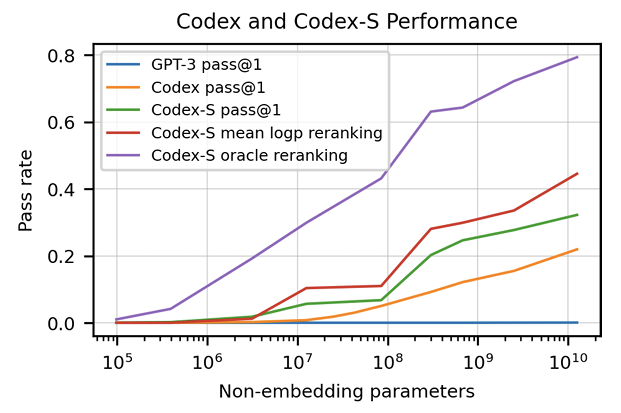
Plus, a scaling law similar to that of GPT-3 is also observed, suggesting better performance can be achieved with even larger models: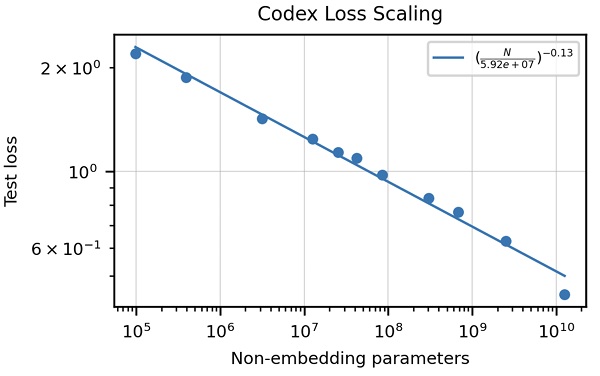
And the authors also noticed that higher temperatures are more preferred for larger k, highlighting the importance of careful hyper-parameter tuning: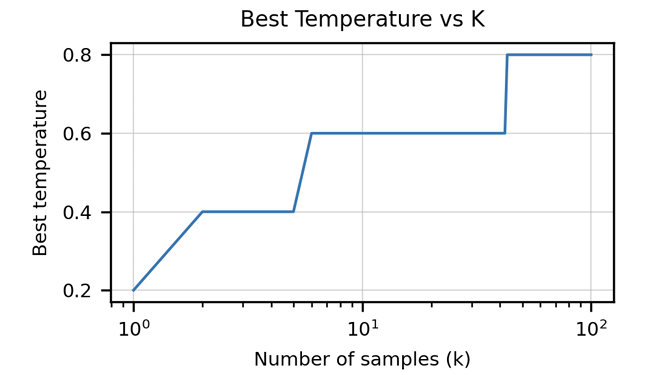
InstructGPT and ChatGPT
Evaluation of Alignment
How to properly evaluate “alignment” is also challenging, as the definition of alignment is not as clear as other aspects such as accuracy. In this work the authors define alignment as if the models are “helpful, honest, and harmless” and convert them to more measurable properties:
- Helpful: by measuring if the model could follow instructions and even infer intentions from a few-shot prompt.
- Honest: by measuring truthfulness, or in the author’s words, “if the model’s statements about the world are true”. More specifically, they propose to measure it by hallucination rate on the TruthfulQA dataset.
- Harmless: by measuring “if an output is inappropriate in the context of a customer assistant, denigrates a protected class, or contains sexual or violent content”, and benchmarking on datasets designed to measure bias and toxicity.
On top of that, to make sure the finetuning process will not cause severe regressions on pre-training performance, the evaluation process also need to reflect quality on both the pre-training and finetuning objectives. For that reason, InstructGPT was evaluated on two separate datasets:
- Evaluations on API distribution: this is mainly for evaluating the finetuning quality, by asking human labelers to rate which output is preferred;
- Evaluations on public NLP datasets: this evaluates both the pre-training and finetuning quality, including traditional NLP datasets as well as datasets for evaluating model safety like truthfulness, toxicity and bias.
Next, we will briefly explain how RLHF works and how it is implemented in InstructGPT.
RLHF (Reinforcement Learning from Human Feedback)
The figure below shows the 5 elements in a typical Reinforcement Learning scenario: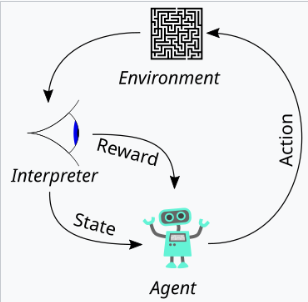
Now imagine you are teaching your puppy to sit, where you can find all the 5 elements:
- Agent: Your puppy learning this new command “sit”.
- Environment: Everything around your puppy.
- State: The situation your puppy is in (whether it is sitting or not).
- Reward: A treat that you give your puppy when it follows your command;
- Action: What your puppy could do, like sitting, jumping or barking.
Reinforcement Learning works like this: In the beginning your dog (agent) didn’t understand what “sit” means, but it will try different things like running, sitting or even barking (actions) in your house (environment). Every time it sits, it will get a treat (reward). Over time your puppy learns that sitting gets a treat and it appears like it finally understands “sit”.
Training a model with RL follows a very similar trial-and-error approach. The key to RL is having a well-designed reward. This reward must be closely aligned with the goal; otherwise the agent will not be able to learn the desired behaviors. Meanwhile, producing such a reward should be as easy and quick as possible, since if it is too slow or too complicated to calculate the reward, the RL process will also become extremely slow, making it less useful in practical tasks.
For example, in a game, every action the agent takes will automatically get a score from the environment, and this score is directly connected to your agent’s performance in playing this game.
However, in many real-world applications, there is no ready-to-use reward like a score in a game. Instead researchers have to take great efforts in defining a proper reward function. Moreover, some desired behaviors are very difficult to translate into reward functions — for example, how could you define a reward function to guide the agent to answer questions more politely?
This leads to RLHF: Reinforcement Learning from Human Feedback.
Again in the puppy training example, imagine your puppy finally learns to sit, but sometimes it also barks while sitting, or it will jump onto the couch first instead of sitting quietly on the floor.
What can you do in that case?
With RLHF, you don’t just give your puppy a treat every time it sits. Instead, you give treats by comparing its behaviors. For example, if the puppy sits quietly on the floor, it gets a bigger reward than if it sits while barking or after jumping onto the couch. This way, your puppy learns that sitting quietly on the floor is better, even though you didn’t explicitly explain what “quiet” means.
As we mentioned before, having an easy and fast reward is the key to RL, which makes it unrealistic to involve a human into the training loop to provide direct feedback. To overcome this issue, we can collect some human feedback first, and then use these feedback to learn a reward function to mimic human preferences when comparing two actions.
In summary, RLHF typically involves three stages:
- Collect human feedback: sampling model outputs, and ask human judges to compare which is better.
- Learn a reward model by mimicking human judge's preferences.
- Train a better policy using the leant reward model in the RL process.
In case you are not familiar with RL terminology: a policy refers to the agent’s strategy to choose actions based on the state of the environment.
Next we will cover how this RLHF approach is implemented in finetuning InstructGPT.
Implementation of RLHF in InstructGPT
InstructGPT and ChatGPT were trained using the same model (see this blog), with RLHF being the key element in finetuning.
The training process largely follows the steps we have introduced in the previous section, with special care on data quality and implementation details, which in my opinion, are equivalently important to make InstructGPT such a success.
Now let me break it down.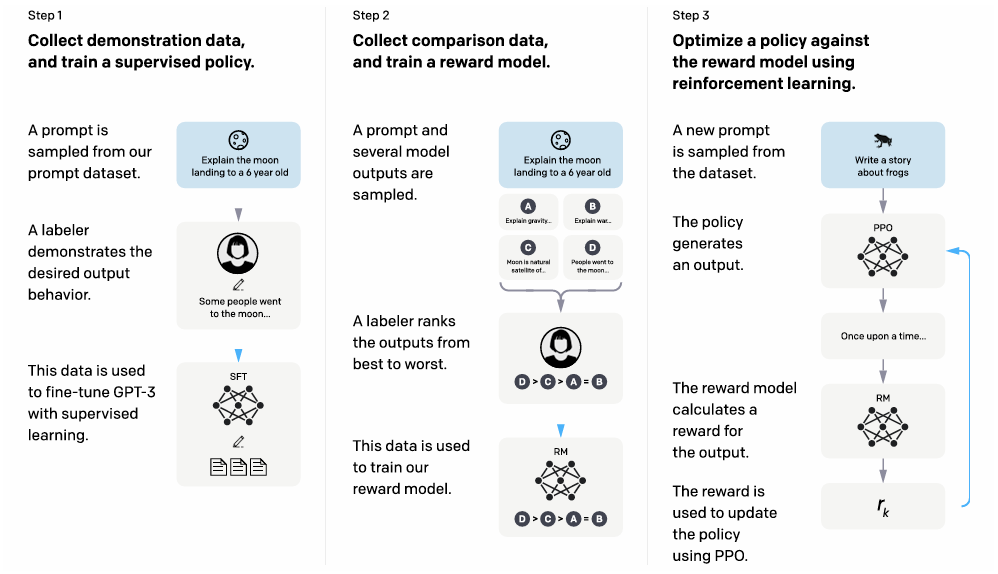
Step 1: Collect demonstration data and train a supervised policy
In this step, human labelers were asked to provide high-quality demonstrations of the desired behavior for each prompt.
Prompt dataset: To begin with, you need to have a prompt dataset from which you can sample individual prompts, and ideally that prompt dataset should be both useful and diverse.
To do that, the authors took an iterative approach: in the very beginning, labelers were asked to manually write some seed prompts, and these data were used to train a model via supervised learning. This model was later deployed to the OpenAI API to collect text prompts from users, which later formed the prompt dataset.
The table below shows the distribution of this prompt dataset, as diversity is very important in making sure the model will be trained on various tasks: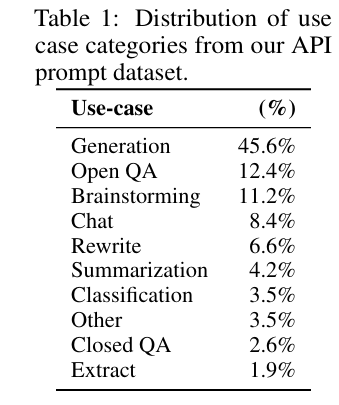
Human data collection: human data are needed in three components throughout the RLHF process, including writing demonstrations in Step 1, providing comparison data in Step 2, and conducting final evaluations after finetuning.
In the paper the authors mentioned many practices to ensure data quality:
- Firstly, high-quality data come from good labelers. To ensure their ability in data labeling, a screening test was conducted to select labelers who were “sensitive to the preferences of different demographic groups, and were good at identifying outputs that were potentially harmful”.
- Secondly, to ensure consistency between all the labelers, an onboarding process was setup to train all labelers, and detailed instructions for each task were provided. The authors also mentioned that they setup a shared chat room to answer questions from labelers.
- Finally, to see how the model generalizes to the preferences of different labelers, a separate group of labelers who didn’t got through the screening test were hired for evaluation.
Based on these human demonstration data, a pretrained GPT-3 model was finetuned using supervised learning in the first step. This model is referred to as the baseline policy, which will be used to produce comparison outputs in Step 2 and initialize the PPO algorithm in Step 3.
Step 2: Collect comparison data and train a reward model
Comparison data collection: Once the baseline policy is available, it is used to generate outputs for some sampled prompts, and these outputs will be reviewed and ranked by human labelers from the best to the worst. To speedup this ranking process, a set of K outputs will be shown simultaneously to the human labelers, where K ranges from 4 to 9.
Reward model training: The reward model was initialized from the supervised baseline policy, by removing the final unembedding layer and training on the comparison data. In particular, the authors mention that training all comparisons from each prompt as a single batch rather than shuffling the comparisons can help alleviate overfitting. It was trained to assign scalar scores to input-response pairs, with 6B parameters. Note that we need to seek a balance when deciding the size of this reward model: it needs to be sufficiently large to accurately mimic human preferences, however it cannot be too large since it needs to support fast inference during the RL process.
Step 3: Optimize a policy using the reward model with PPO
At this point we have got everything ready to finetune the model with RLHF: the initial policy and the reward model. The training in this step follows a typical RL process: in each episode, a new prompt is sampled (the “state”) and new outputs will be generated (the model’s “action”) by the current policy (the “agent”), and then the reward model will calculate a reward for the output (“reward”), according to which the policy will be updated using PPO.
Don’t worry if you are not familiar with PPO — it is simply a method designed to help the agent to slowly update its strategies.
A few things to mention here:
- A per-token KL penalty is added at each token to mitigate the over-optimization of the reward model.
- The authors further experimented with mixing the pretraining gradients into the PPO gradients, in order to fix the performance regressions on public NLP datasets (such regressions are often called “the alignment tax”), which was referred to as “PPO-ptx”. In this paper, InstructGPT actually refers to the PPO-ptx models.
Note that Step 2 and Step 3 can be iterated continuously:
- With an updated policy (from Step 3), we can generate new outputs and collect more comparison data, which can be used to train a new reward model by repeating Step 2;
- With a new reward model (from Step 2), we can get a better policy by repeating Step 3.
Findings in Evaluation
Due to space limitation we will not go through all the evaluation results in this article, instead we will just highlight several new findings.
As perhaps the most important finding, results show that RLHF can indeed improve alignment. The figure below shows the win rate against the supervised 175B GPT3 model, evaluated by human judges. According to this figure, both PPO and PPO-ptx significantly outperform the GPT baselines, where even the 1.3B PPO models are better than the 175B GPT-3. This result clearly demonstrates the effectiveness of RLHF.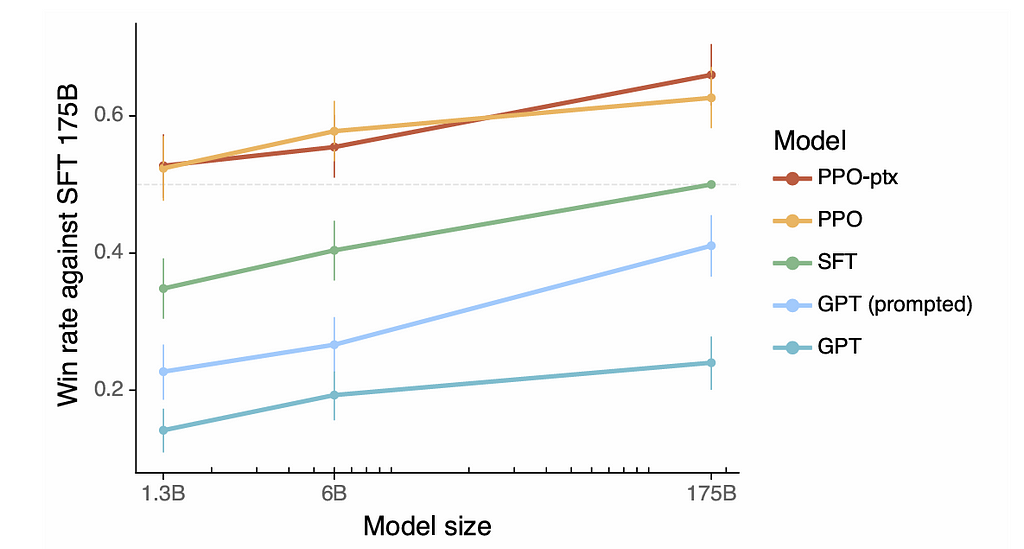
The authors also found that InstructGPT show improves in truthfulness (hallucination rate reduced from 41% to 21%), slight improvements in toxicity (25% fewer toxic outputs), but no significant improvements on reducing bias.
Another finding is that PPO-ptx can minimize performance regressions on public NLP datasets, as shown in the figure below.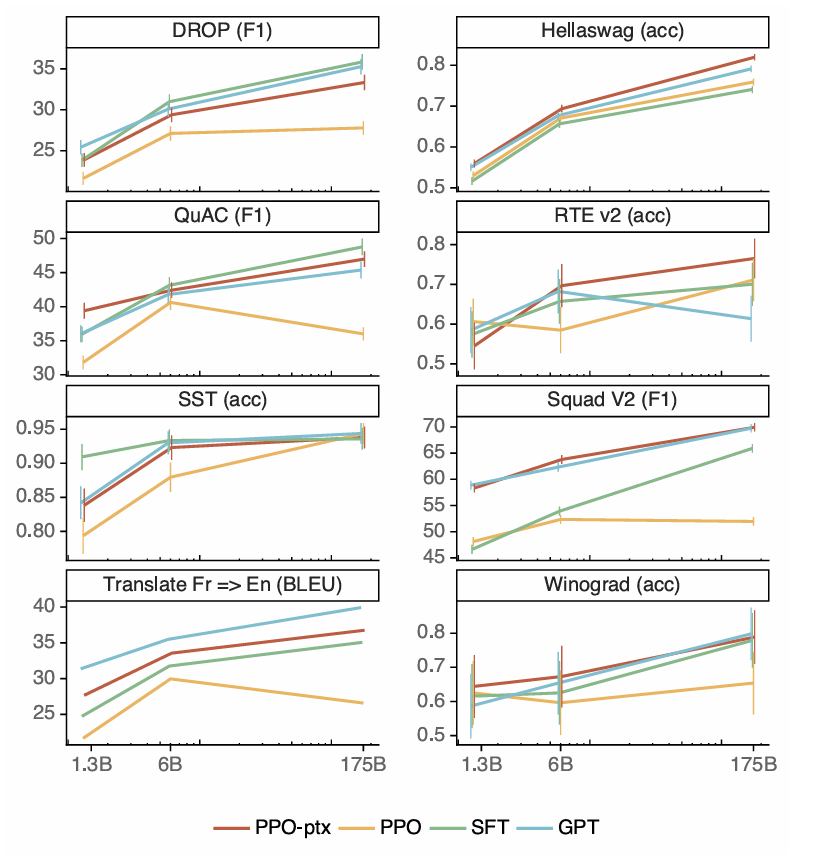
Summary
Training a LLM usually involves multiple stages like pre-training, supervised finetuning, and alignment with RLHF. For our tasks at hand, we can usually start from an open-source, pre-trained LLM and finetune it on domain-specific data.
A few questions to ask while finetuning your own LLMs (though this is not meant to be an exhaustive list):
- Do we have a clear definition on the model’s desired behaviors? How can we evaluate such behaviors? If no available metrics to use, can we create one by ourselves?
- Do we have available training data? If not, how can we collect such data by ourselves? If human labelers are needed, how to ensure their labeling quality?
- What kind of cleaning or pre-processing is needed? Any heuristics can we use to check the data quality?
- Does our data cover a wide range of scenarios?
- Do we need to modify our tokenizers? Do we need to modify the model structures? Do we need to add auxiliary finetuning objectives?
- Does finetuning lead to regression on pre-training performance? Can we seek a balance?
- Does finetuning lead to some unexpected negative behaviors? How can we mitigate that?
- How to prevent overfitting in the finetuning process?
- What hyper-parameters can we tune during finetuning or during evaluation? Any heuristics we can leverage?
In the end of the day, exploring a new task is always both challenging and exciting, and I hope the learnings from this article can help make it less challenging, more exciting, and ultimately more enjoyable :)
Thanks for reading!
Understanding the Evolution of ChatGPT: Part 3— Insights from Codex and InstructGPT was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.






