A Guide To Time-Series Sensor Data Classification using UCI HAR Data
A Guide To Time-Series Sensor Data Classification using UCI HAR Data
A Guide to Time-Series Sensor Data Classification Using UCI HAR DataUsing TS-Fresh, scikit-learn, and Data Studio to classify sensor dataImage by authorThe world is full of sensors generating time-series data, and extracting meaningful insights from this data is a crucial skill in today’s data-driven world. This article provides a hands-on guide to classifying human activity using sensor data and machine learning. We’ll walk you through the entire process, from preparing the data to building and validating a model that can accurately recognize different activities like walking, sitting, and standing. By the end of this article you will have worked through a practical machine learning application and gained valuable experience in analyzing real-world sensor data.Project OverviewThe UCI Human Activity Recognition (HAR) dataset is great for learning how to classify time-series sensor data using machine learning. In this article, we will:Streamline dataset preparation and exploration with the Data StudioCreate a feature extraction pipeline using TSFreshTrain a machine learning classifier using scikit-learnValidating your model's accuracy using the Data StudioThe ToolsThe UCI HAR dataset captures six fundamental activities (walking, walking upstairs, walking downstairs, sitting, standing, lying) using smartphone sensors. It’s a great starting point for understanding human movement patterns, time-series data, and modeling. This dataset is licensed under a Creative Commons Attribution 4.0 International (CC BY 4.0) license.SensiML Data Studio provides an intuitive GUI interface to machine learning dataset. It has tools for managing, annotating, and visualizing time-series sensor data-based machine-learning projects. The powerful tools make it easier to explore different features as well as identify problem areas your data set and models. The community version is free to use with paid options available.TSFresh is a Python library specifically designed for extracting meaningful features from time series data. It is used for analysis, as well as preprocessing features to send to classification, regression, or clustering algorithms. TSFresh will automatically calculate a wide range of features from its built-in feature library such as statistical and frequency-based features. If you need a specific feature, it is easy to add custom features.Scikit-learn: is a free machine learning library for Python. It provides simple and efficient tools for predictive data analysis, including classification, regression, clustering, and dimensionality reduction.Step-by-Step Guide:Prepare the Dataset for Model trainingThe UCI dataset is pre-split into chunks of data, which makes it difficult to visualize and train models against. This Python script converts the UCR project into a single CSV file per user and activity. It also stores the metadata in a .dai file. The converted project is available directly on GitHub here.You can import the converted project into the data studio from the .dai file into the SensiML Data Studio.Image by authorOpen the project explorer and select the file 1_WALKING.CSV. When you open this file, you will see 95 labeled segments in the Label Session of this project.A) The labels from the UCR data set that correspond to each event and are synced with the sensor data. B) A detailed view of the labels that can be searched and filtered. C) The total time of this sensor data is 4 minutes and 3 seconds. The total number of samples is 12,160. Image by authorThe UCR dataset defaults to events of 128 samples each. However, that is not necessarily the best segment size for our project. Additionally, when building out a training dataset, its helpful to augment the data using an overlap of the events. To change the way data is labeled, we create a Sliding Windowing function. We’ve implemented a sliding window function here that you can import into the Data Studio. Download and import the sliding window as a new model:File->Import Python ModelNavigate and select the file you just downloadedGive the model the name Sliding Window and click NextSet the window size to 128 and the delta to 64 and click SaveNote: To use Python code you need to set the Python path for the Data Studio. Go to Edit->Settings->General Navigate to and Select the .dll file for the Python environment you want to use.Now that you have imported the sliding window segmentation algorithm as a model, we can create new segments using the algorithm.Click on the model tab in the top right Capture Explore Section.Right-Click on the model and Select Run ModelClick on one of the new labels and click CTL + A to select them all.Click edit label and select the appropriate label for the file, in this case walking.You should now see 188 overlapping labels in the file. Using the sliding window augmentation allowed us to double the size of our training set. Each segment is different enough that it shouldn’t introduce bias into our dataset searching for the model's hyperp
A Guide to Time-Series Sensor Data Classification Using UCI HAR Data
Using TS-Fresh, scikit-learn, and Data Studio to classify sensor data
Image by author
The world is full of sensors generating time-series data, and extracting meaningful insights from this data is a crucial skill in today’s data-driven world. This article provides a hands-on guide to classifying human activity using sensor data and machine learning. We’ll walk you through the entire process, from preparing the data to building and validating a model that can accurately recognize different activities like walking, sitting, and standing. By the end of this article you will have worked through a practical machine learning application and gained valuable experience in analyzing real-world sensor data.
Project Overview
The UCI Human Activity Recognition (HAR) dataset is great for learning how to classify time-series sensor data using machine learning. In this article, we will:
Streamline dataset preparation and exploration with the Data Studio
Create a feature extraction pipeline using TSFresh
Train a machine learning classifier using scikit-learn
Validating your model's accuracy using the Data Studio
The Tools
The UCI HAR dataset captures six fundamental activities (walking, walking upstairs, walking downstairs, sitting, standing, lying) using smartphone sensors. It’s a great starting point for understanding human movement patterns, time-series data, and modeling. This dataset is licensed under a Creative Commons Attribution 4.0 International (CC BY 4.0) license.
SensiML Data Studio provides an intuitive GUI interface to machine learning dataset. It has tools for managing, annotating, and visualizing time-series sensor data-based machine-learning projects. The powerful tools make it easier to explore different features as well as identify problem areas your data set and models. The community version is free to use with paid options available.
TSFresh isa Python library specifically designed for extracting meaningful features from time series data. It is used for analysis, as well as preprocessing features to send to classification, regression, or clustering algorithms. TSFresh will automatically calculate a wide range of features from its built-in feature library such as statistical and frequency-based features. If you need a specific feature, it is easy to add custom features.
Scikit-learn: is a free machine learning library for Python. It provides simple and efficient tools for predictive data analysis, including classification, regression, clustering, and dimensionality reduction.
Step-by-Step Guide:
Prepare the Dataset for Model training
The UCI dataset is pre-split into chunks of data, which makes it difficult to visualize and train models against. This Python script converts the UCR project into a single CSV file per user and activity. It also stores the metadata in a .dai file. The converted project is available directly on GitHub here.
You can import the converted project into the data studio from the .dai file into the SensiML Data Studio.Image by author
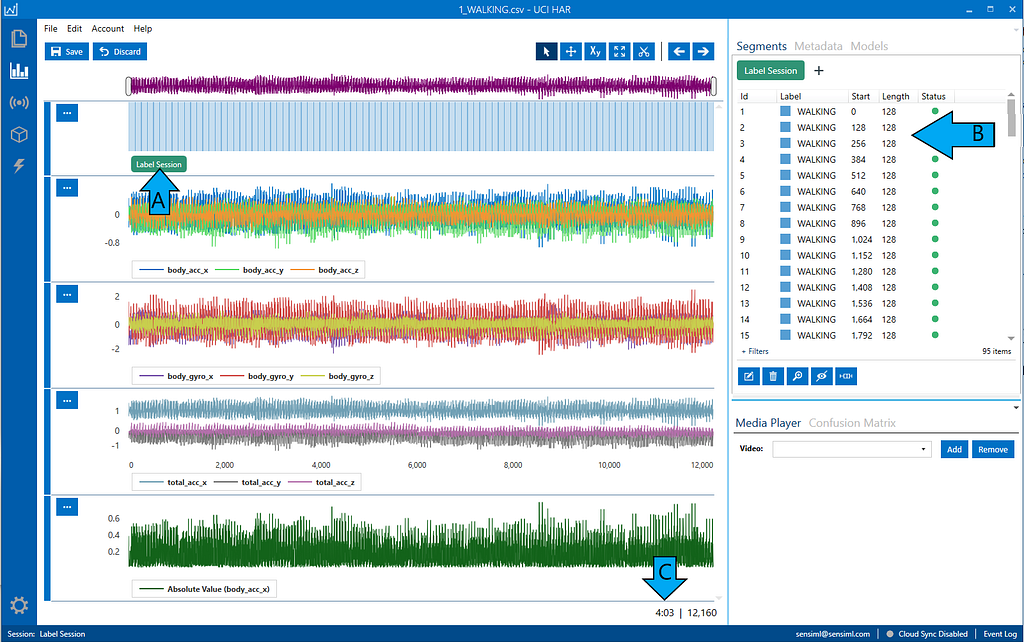
Open the project explorer and select the file 1_WALKING.CSV. When you open this file, you will see 95 labeled segments in the Label Session of this project.A) The labels from the UCR data set that correspond to each event and are synced with the sensor data. B) A detailed view of the labels that can be searched and filtered. C) The total time of this sensor data is 4 minutes and 3 seconds. The total number of samples is 12,160. Image by author
The UCR dataset defaults to events of 128 samples each. However, that is not necessarily the best segment size for our project. Additionally, when building out a training dataset, its helpful to augment the data using an overlap of the events. To change the way data is labeled, we create a Sliding Windowingfunction. We’ve implemented a sliding window function here that you can import into the Data Studio. Download and import the sliding window as a new model:
File->Import Python Model
Navigate and select the file you just downloaded
Give the model the name Sliding Window and click Next
Set the window size to 128 and the delta to 64 and click Save
Note: To use Python code you need to set the Python path for the Data Studio. Go to Edit->Settings->General Navigate to and Select the .dll file for the Python environment you want to use.
Now that you have imported the sliding window segmentation algorithm as a model, we can create new segments using the algorithm.
Click on the model tab in the top right Capture Explore Section.
Right-Click on the model and Select Run Model
Click on one of the new labels and click CTL + A to select them all.
Click edit label and select the appropriate label for the file, in this case walking.
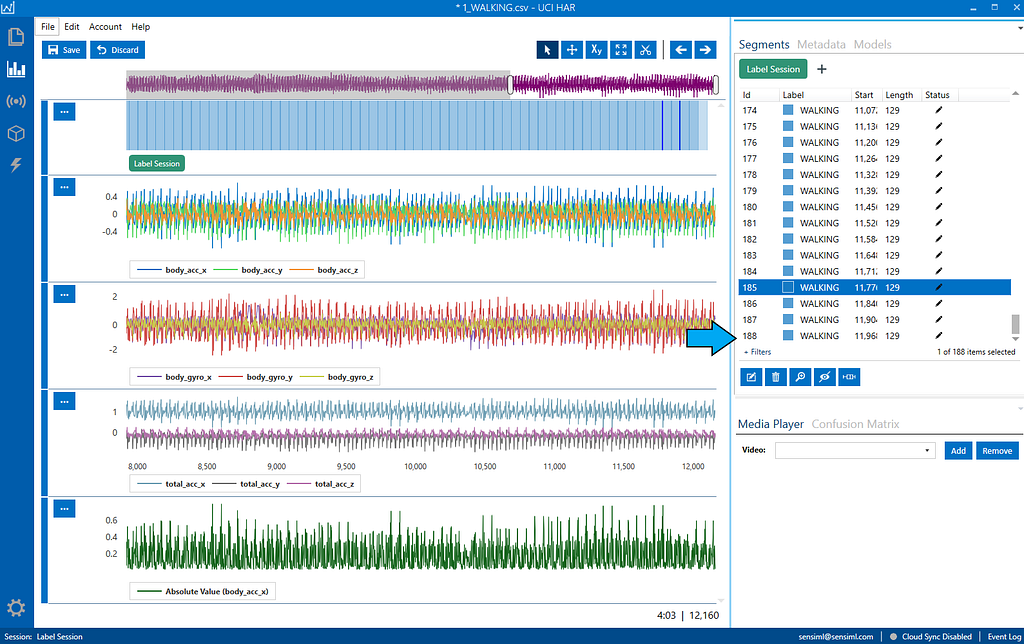
You should now see 188 overlapping labels in the file. Using the sliding window augmentation allowed us to double the size of our training set. Each segment is different enough that it shouldn’t introduce bias into our dataset searching for the model's hyperparameters, but you should still consider splitting across different users when generating your folds instead of single files. You can customize the sliding window function or add your segmentation algorithms to the Data Studio to help label and then your own data sets.Image by author
Feature Engineering
The sensor data for this data set has 9 channels of data (X, Y, and Z for body acceleration, gyroscope, and total acceleration). For segment sizes of 128, that means we have 128*9=1152 features in the segment. Instead of feeding the raw sensor data into our machine-learning model, we use feature extractors to compute relevant features from the datasets. This allows us to reduce the dimensionality, reduce the noise, and remove biases from the dataset.
Using TSFresh, each labeled segment will be converted into a group of features called a feature vector that can be used to train a machine learning model.
We will use a Jupyter Notebook to train the model. You can get the full notebook here. The first thing you will need is the SensiML Python Clients Data Studio library which we can use to programmatically access the data in the local Data Studio project.
!pip install SensiML
Import the DCLProject API and connect to the local UCI HAR project file. You can right-click on a file in the project explorer of the Data Studio and click Open In Explorer to find the path of the project.
from sensiml.dclproj import DCLProject ds = DCLProject(path=r"
Next we are going to pull in all of the data segments from that are part of the session “Label Session. This will return a DataSegments object containing all of the DataSegments in the specified session. The DataSegments object holds DataSegment objects which store metadata and raw data for each segment. The DataSegments object also has built-in visualization and conversion APIs
Next, filter the DataSegments so we only include ones that are part of our training set (ie metadata Set==Train) and convert to the time-series format to use as input into TSFresh.
train_segments = segments.filter_by_metadata({"Set":["Train"]}) timeseries, y = train_segments.to_timeseries()
Import TSFresh for feature extraction methods
from tsfresh import select_features, extract_features from tsfresh.feature_selection.relevance import calculate_relevance_table
Use the TSFrsesh extract_features method to generate lots of features from each DataSegment. To save processing time, initially generate features on a subset of the data.
timeseries, y = train_segments.to_timeseries() X = extract_features(timeseries[timeseries["id"]<1000], column_id="id", column_sort="time")
Split the dataset into train and test so we can validate the hyperparameters we select
Using the select_feature API from TSFresh, filter out features that are not significant to the model. You can read the tsfresh documentation for more information.
Now that we have our training dataset we can start building a machine learning model. In this tutorial, we will stick with a single classifier and training algorithm, in practice you would typically do a more exhaustive search across classifiers to tune for the best model.
from sklearn.ensemble import RandomForestClassifier from sklearn.model_selection import train_test_split from sklearn.metrics import classification_report, confusion_matrix, ConfusionMatrixDisplay, f1_score
We can filter the number of features down even more by computing the relevance table of the filtered features. We then do a search for the lowest number of features that provide a good model. Since computing features can be CPU intensive and too many features make it easier for the model to overfit, we try to reduce the number of features without affecting performance.
Using the TSFresh kind_to_fc_parameters parameter, we can generate 120 relevant features for the entire training dataset and use that to train our model.
from tsfresh.feature_extraction.settings import from_columns
kind_to_fc_parameters = from_columns(X_train_relevant_features) timeseries, y = segments.to_timeseries()
Now that we have a trained model and feature extraction pipeline, we dump the model into a pickle file and dump the kind_to_fc_parameters into a json. We will use those in the Data Studio to load the model and extract the features there.
import pickle import json
with open('model.pkl', 'wb') as out: pickle.dump(classifier_selected_multi, out)
With the saved model we will use the Data Studio to visualize and validate the model accuracy against our test data set. To validate the model in the Data Studio, import the model.py into your Data Studio project.
Go to File->Import Python Model.
Select the path to the model.pkl and the fc_params.json as the two parameters in the model
Set the window size to 128 and the delta to 128. After importing the model, open the WALKING_1.CSV file again
. Go to the capture info on the top right and select the model tab. Click the newly imported model and Select Run Model.
It will give you the option to create a new Test Model session, select yes to save the segments that are generated the Test Session.
Select Compare Sessions in capture info and select the test model.
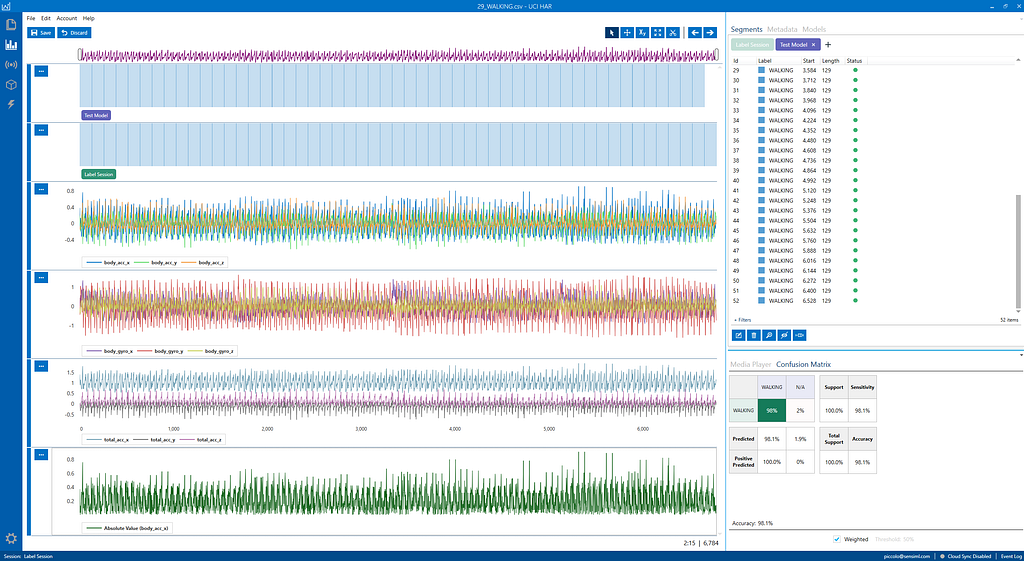
This will allow you to see the ground truth and model results overlayed with the sensor data. In the capture info area in the bottom right, click on the confusion matrix tab. This shows the performance of the model against the test session.Image by author
Conclusion
In this guide we walked through using the SensiML Data Studio to annotate and visualize the UCI HAR dataset, leveraged TSFresh to create a feature extraction pipeline, scikit-learn to train a random forest classifier, and finally the Data Studio to validate the trained model against our test data set. By leveraging sci-kit learn, TSFresh and the Data Studio, you are able to perform all of the tasks required for building a machine learning classification pipeline for time series data starting from from labeling to and ending in model validation.

 Editor-Admin
Editor-Admin