
LyRec: A Song Recommender That Reads Between the Lyrics
This is how I built an emotionally intelligent LLM-powered song recommendation system.Photo by David Pupăză on UnsplashDo you remember the last time you found yourself obsessing over a song? Maybe it was the raw emotion that resonated with you, or perhaps it was the lyrics that kept you hooked. Or maybe you loved the story it tells. Wouldn’t it be nice if there was a way to find songs that express a similar emotion, share similar lyrical elements, or paint similar imagery?In this article, I’ll show you how I built LyRec (see what I did there? ????), a recommendation system for songs that lets you do this! Here’s a little demo (it runs on my Mac!).Don’t worry; you won’t need to know the nitty-gritty of recommendation systems to understand this. Along the way, I’ll explain my design choices, and hopefully, you’ll learn a thing or two about semantic search and Retrieval-Augmented Generation (RAG). So let’s get started!Settings the Goals ????First, I needed to set some realistic goals for LyRec. Here’s the list I finalized.1. Given a (seen or unseen) song lyrics, LyRec should be able to suggest similar songs from its database.2. Given a free-form text input, LyRec should be able to find songs that match this description. The text input may describe an emotion, mood, story, specific elements, and so on.3. Given both lyrics and description, LyRec should be able to find the best matching songs.The Approach ????With the goals set, it was time to come up with a suitable approach for these tasks. I decided to go with an embedding-based semantic search. If you are unfamiliar with this concept, here’s a quick overview.Semantic search is a technique where we search (given a query) a database by understanding the contextual meaning of words rather than relying solely on keyword matching. The increasingly popular way of doing this is with higher dimensional vector embeddings. First, using a language model, we compute a vector representation (embedding) for each entry in our database and store it alongside. When a new query comes, we generate its embedding using the same model and compute the similarity between the query embedding and all the embeddings stored in the database. Finally, we return the entry with the highest embedding similarity.For LyRec, the entries would be song lyrics, and the query would be either new song lyrics or a user-written free-form text. So, we would essentially compute semantic similarity between lyrics embeddings and the query. Initially, this is where I stopped.After giving it some more thought, I realized that while computing the similarity between two lyrics embeddings was fine, it was probably not ideal to compute the similarity between textual description and lyrics. So, I decided to generate another set of embeddings that would capture the description of the songs. But how do I get those song descriptions? Easy! I just asked another LLM to summarize each song in our database. Then, I used the previous model to generate embeddings from these summaries. So, when the query is a free-form text, LyRec would use these summary embeddings to compute semantic similarities.Okay, now LyRec has two ways to find similar songs. But what if we wanted to use both song lyrics and a description for a recommendation? Well, there could be many ways to combine lyrics and summary similarity scores. But I took a slightly different route of re-ranking.In RAGs, re-ranking is often done with a model (trained for predicting relevance scores), which is more accurate (but costlier) than embedding similarity. The initially retrieved documents (based on embedding similarity) and the query are passed to this re-ranker, which assigns a relevance score to each document. Then, based on this new score, the documents are reordered.Taking inspiration from this, I came up with the following approach. First, LyRec will fetch the most similar songs based on the lyrics embedding, and then these songs will be re-ranked based on the summary embedding similarity scores. It’s worth pointing out that I am not using a re-ranker model. Instead, I’m just using a different embedding for the re-ranking step. You may ask, why not use summary embeddings in the first step and lyrics embeddings in the second? Well, to be honest, I don’t have a good answer to that. I just preferred the outputs more (for a small set of queries) using this method. Maybe you can try the other way!I hope the overall approach is now clear. Let’s get into the implementation!The Implementation ????????DatasetOf course, the first thing I needed was a song lyrics dataset. Fortunately, I found one on Kaggle! This dataset is under a Creative Commons (CC0: Public Domain) license.Spotify Million Song DatasetThis dataset contains about 60K song lyrics along with the title and artist name. I know 60K might not cover all the songs you love, but I think it’s a good starting point for LyRec.songs_df = pd.read_csv(f"{root_dir}/spotify_millsongdata.csv")songs_df = songs_df.drop(
 Editor-Admin
Editor-Admin
This is how I built an emotionally intelligent LLM-powered song recommendation system.
Do you remember the last time you found yourself obsessing over a song? Maybe it was the raw emotion that resonated with you, or perhaps it was the lyrics that kept you hooked. Or maybe you loved the story it tells. Wouldn’t it be nice if there was a way to find songs that express a similar emotion, share similar lyrical elements, or paint similar imagery?
In this article, I’ll show you how I built LyRec (see what I did there? ????), a recommendation system for songs that lets you do this! Here’s a little demo (it runs on my Mac!).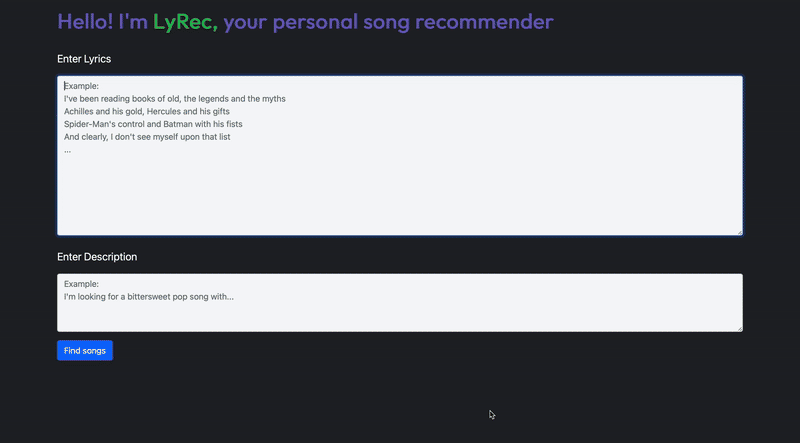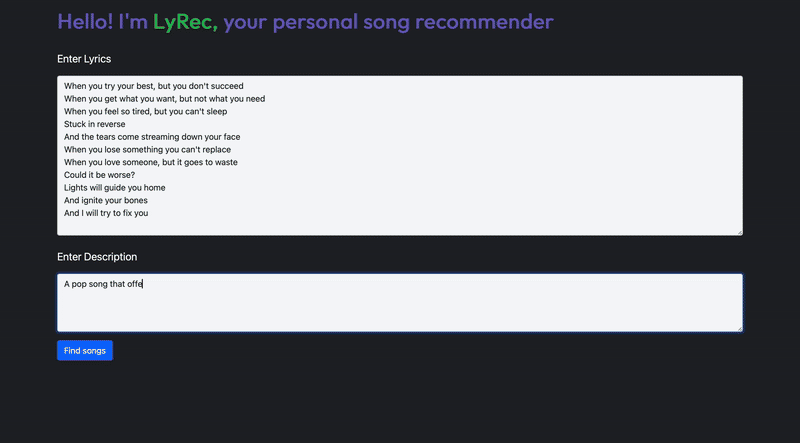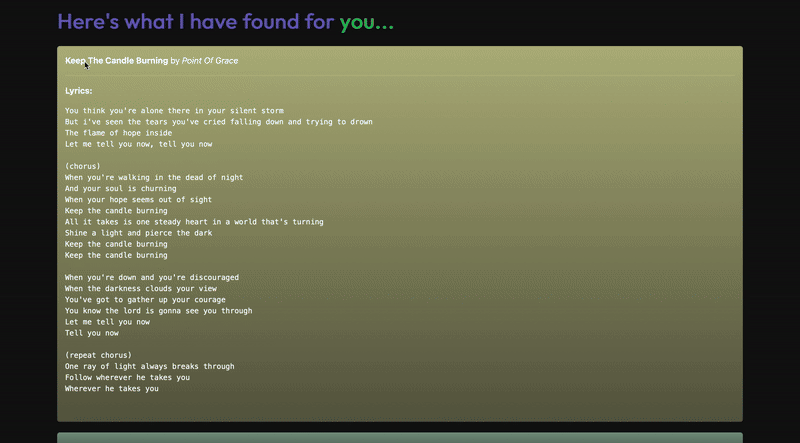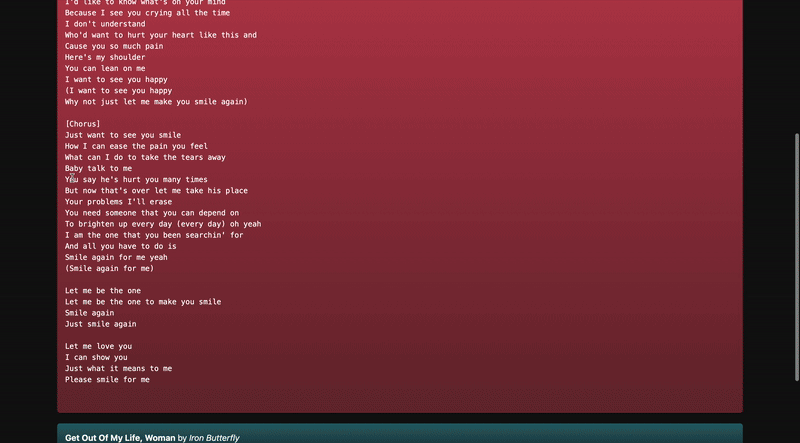
Don’t worry; you won’t need to know the nitty-gritty of recommendation systems to understand this. Along the way, I’ll explain my design choices, and hopefully, you’ll learn a thing or two about semantic search and Retrieval-Augmented Generation (RAG). So let’s get started!
Settings the Goals ????
First, I needed to set some realistic goals for LyRec. Here’s the list I finalized.
1. Given a (seen or unseen) song lyrics, LyRec should be able to suggest similar songs from its database.
2. Given a free-form text input, LyRec should be able to find songs that match this description. The text input may describe an emotion, mood, story, specific elements, and so on.
3. Given both lyrics and description, LyRec should be able to find the best matching songs.
The Approach ????
With the goals set, it was time to come up with a suitable approach for these tasks. I decided to go with an embedding-based semantic search. If you are unfamiliar with this concept, here’s a quick overview.
Semantic search is a technique where we search (given a query) a database by understanding the contextual meaning of words rather than relying solely on keyword matching. The increasingly popular way of doing this is with higher dimensional vector embeddings. First, using a language model, we compute a vector representation (embedding) for each entry in our database and store it alongside. When a new query comes, we generate its embedding using the same model and compute the similarity between the query embedding and all the embeddings stored in the database. Finally, we return the entry with the highest embedding similarity.
For LyRec, the entries would be song lyrics, and the query would be either new song lyrics or a user-written free-form text. So, we would essentially compute semantic similarity between lyrics embeddings and the query. Initially, this is where I stopped.
After giving it some more thought, I realized that while computing the similarity between two lyrics embeddings was fine, it was probably not ideal to compute the similarity between textual description and lyrics. So, I decided to generate another set of embeddings that would capture the description of the songs. But how do I get those song descriptions? Easy! I just asked another LLM to summarize each song in our database. Then, I used the previous model to generate embeddings from these summaries. So, when the query is a free-form text, LyRec would use these summary embeddings to compute semantic similarities.
Okay, now LyRec has two ways to find similar songs. But what if we wanted to use both song lyrics and a description for a recommendation? Well, there could be many ways to combine lyrics and summary similarity scores. But I took a slightly different route of re-ranking.
In RAGs, re-ranking is often done with a model (trained for predicting relevance scores), which is more accurate (but costlier) than embedding similarity. The initially retrieved documents (based on embedding similarity) and the query are passed to this re-ranker, which assigns a relevance score to each document. Then, based on this new score, the documents are reordered.
Taking inspiration from this, I came up with the following approach. First, LyRec will fetch the most similar songs based on the lyrics embedding, and then these songs will be re-ranked based on the summary embedding similarity scores. It’s worth pointing out that I am not using a re-ranker model. Instead, I’m just using a different embedding for the re-ranking step. You may ask, why not use summary embeddings in the first step and lyrics embeddings in the second? Well, to be honest, I don’t have a good answer to that. I just preferred the outputs more (for a small set of queries) using this method. Maybe you can try the other way!
I hope the overall approach is now clear. Let’s get into the implementation!
The Implementation ????????
Dataset
Of course, the first thing I needed was a song lyrics dataset. Fortunately, I found one on Kaggle! This dataset is under a Creative Commons (CC0: Public Domain) license.
This dataset contains about 60K song lyrics along with the title and artist name. I know 60K might not cover all the songs you love, but I think it’s a good starting point for LyRec.
songs_df = pd.read_csv(f"{root_dir}/spotify_millsongdata.csv")
songs_df = songs_df.drop(columns=["link"])
songs_df["song_id"] = songs_df.index + 1I didn’t need to perform any pre-processing on this data. I just removed the link column and added an ID for each song.
Models
I needed to select two LLMs: One for computing the embeddings and another for generating the song summaries. Picking the correct LLM for your task may be a little tricky because of the sheer number of them! It’s a good idea to look at the leaderboard to find the current best ones. For the embedding model, I checked the MTEB leaderboard hosted by HuggingFace.
MTEB Leaderboard - a Hugging Face Space by mteb
I was looking for a smaller model (obviously!) without compromising too much accuracy; hence, I decided on GTE-Qwen2-1.5B-Instruct.
from sentence_transformers import SentenceTransformer
import torch
model = SentenceTransformer(
"Alibaba-NLP/gte-Qwen2-1.5B-instruct",
model_kwargs={"torch_dtype": torch.float16}
)
For the summarizer, I just needed a small enough instruction following LLM, so I went with Gemma-2–2b-It. In my experience, it’s one of the best small models as of now.
import torch
from transformers import pipeline
pipe = pipeline(
"text-generation",
model="google/gemma-2-2b-it",
model_kwargs={"torch_dtype": torch.bfloat16},
device="cuda",
)
Pre-computing the Embeddings
Computing the lyrics embeddings was pretty straightforward. I just used the .encode(…) method with a batch_size of 32 for faster processing.
song_lyrics = songs_df["text"].values
lyrics_embeddings = model.encode(
song_lyrics,
batch_size=32,
show_progress_bar=True
)
np.save(f"{root_dir}/60k_song_lyrics_embeddings.npy", lyrics_embeddings)
At this point, I stored these embeddings in a .npy file. I could have used a more structured format, but it did the job for me.
Coming to the summary embeddings, I first needed to generate the summaries. I had to ensure that the summary captured the emotion and the song’s theme while not being too lengthy. So, I came up with the following prompt for Gemma-2.
You are an expert song summarizer. \
You will be given the full lyrics to a song. \
Your task is to write a concise, cohesive summary that \
captures the central emotion, overarching theme, and \
narrative arc of the song in 150 words.
{song lyrics}
Here’s the code snippet for summary generation. For simplicity, the following shows a sequential processing. I have included the batch-processing version in the GitHub repo.
def get_summary(song_lyrics):
messages = [
{"role": "user",
"content": f'''You are an expert song summarizer. \
You will be given the full lyrics to a song. \
Your task is to write a concise, cohesive summary that \
captures the central emotion, overarching theme, and \
narrative arc of the song in 150 words.\n\n{song_lyrics}'''},
]
outputs = pipe(messages, max_new_tokens=256)
assistant_response = outputs[0]["generated_text"][-1]["content"].strip()
return assistant_response
songs_df["summary"] = songs_df["text"].progress_apply(get_description)
Unsurprisingly, this step took the most time. Luckily, this needs to be done only once, and of course, when we want to update the database with new songs.
Then, I computed and stored the embedding just like the last time.
song_summary = songs_df["summary"].values
summary_embeddings = model.encode(
song_summary,
batch_size=32,
show_progress_bar=True
)
np.save(f"{root_dir}/60k_song_summary_embeddings.npy", summary_embeddings)
Vector Search
With the embeddings in place, it was time to implement the semantic search based on embedding similarity. There are a lot of awesome open-source vector databases available for this job. I decided to use a simple one called FAISS (Facebook AI Similarity Search). It just takes two lines to add the embeddings into the database. First, we create a FAISS index. Here, we need to mention the similarity metric you want to utilize for searching and the dimension of the vectors. I used the dot product (inner product) as the similarity measure. Then, we add the embeddings to the index.
Note: Our database is small enough to do an exhaustive search using dot product. For larger databases, it’s recommended to perform an approximate nearest neighbor (ANN) search. FAISS has support for that.
import faiss
lyrics_embeddings = np.load(f"{root_dir}/60k_song_lyrics_embeddings.npy")
lyrics_index = faiss.IndexFlatIP(lyrics_embeddings.shape[1])
lyrics_index.add(lyrics_embeddings.astype(np.float32))
summary_embeddings = np.load(f"{root_dir}/60k_song_summary_embeddings.npy")
summary_index = faiss.IndexFlatIP(summary_embeddings.shape[1])
summary_index.add(summary_embeddings.astype(np.float32))
To find the most similar songs given a query, we first need to generate the query embedding and then call the .search(…) method on the index. Under the hood, this method computes the similarity between the query and every entry in our database and returns the top k entries and the corresponding scores. Here’s the code performing a semantic search on lyrics embeddings.
query_lyrics = 'Imagine the last song you fell in love with'
query_embedding = model.encode(f'''Instruct: Given the lyrics, \
retrieve relevant songs\nQuery: {query_lyrics}''')
query_embedding = query_embedding.reshape(1, -1).astype(np.float32)
lyrics_scores, lyrics_ids = lyrics_index.search(query_embedding, 10)
Notice that I added a simple prompt in the query. This is recommended for this model. The same applies to the summary embeddings.
query_description = 'Describe the type of song you wanna listen to'
query_embedding = model.encode(f'''Given a description, \
retrieve relevant songs\nQuery: {query_description}''')
query_embedding = query_embedding.reshape(1, -1).astype(np.float32)
summary_scores, summary_ids = summary_index.search(query_embedding, k)
Pro tip: How do you do a sanity check?
Just put any entry from the database in the query and see if the search returns the same as the top-scoring entry!
Implementing the Features
At this stage, I had the building blocks of LyRec. Now, it was the time to put these together. Remember the three goals I set in the beginning? Here’s how I implemented those.
To keep things tidy, I created a class named LyRec that would have a method for each feature. The first two features are pretty straightforward to implement.
The method .get_songs_with_similar_lyrics(…) takes a song (lyrics) and a whole number k as input and returns a list of k most similar songs based on the lyrics similarity. Each element in the list is a dictionary containing the artist’s name, song title, and lyrics.
Similarly, .get_songs_with_similar_description(…) takes a free-form text and a whole number k as input and returns a list of k most similar songs based on the description.
Here’s the relevant code snippet.
class LyRec:
def __init__(self, songs_df, lyrics_index, summary_index, embedding_model):
self.songs_df = songs_df
self.lyrics_index = lyrics_index
self.summary_index = summary_index
self.embedding_model = embedding_model
def get_records_from_id(self, song_ids):
songs = []
for _id in song_ids:
songs.extend(self.songs_df[self.songs_df["song_id"]==_id+1].to_dict(orient='records'))
return songs
def get_songs_with_similar_lyrics(self, query_lyrics, k=10):
query_embedding = self.embedding_model.encode(
f"Instruct: Given the lyrics, retrieve relevant songs\n Query: {query_lyrics}"
).reshape(1, -1).astype(np.float32)
scores, song_ids = self.lyrics_index.search(query_embedding, k)
return self.get_records_from_id(song_ids[0])
def get_songs_with_similar_description(self, query_description, k=10):
query_embedding = self.embedding_model.encode(
f"Instruct: Given a description, retrieve relevant songs\n Query: {query_description}"
).reshape(1, -1).astype(np.float32)
scores, song_ids = self.summary_index.search(query_embedding, k)
return self.get_records_from_id(song_ids[0])
The final feature was a little tricky to implement. Recall that we need to first retrieve the top songs based on lyrics and then re-rank them based on the textual description. The first retrieval was easy. For the second one, we only need to consider the top-scoring songs. I decided to create a temporary FAISS index with the top songs and then search for the songs with the highest summary similarity scores. Here’s my implementation.
def get_songs_with_similar_lyrics_and_description(self, query_lyrics, query_description, k=10):
query_lyrics_embedding = self.embedding_model.encode(
f"Instruct: Given the lyrics, retrieve relevant songs\n Query: {query_lyrics}"
).reshape(1, -1).astype(np.float32)
scores, song_ids = self.lyrics_index.search(query_lyrics_embedding, 500)
top_k_indices = song_ids[0]
summary_candidates = []
for idx in top_k_indices:
emb = self.summary_index.reconstruct(int(idx))
summary_candidates.append(emb)
summary_candidates = np.array(summary_candidates, dtype=np.float32)
temp_index = faiss.IndexFlatIP(summary_candidates.shape[1])
temp_index.add(summary_candidates)
query_description_embedding = self.embedding_model.encode(
f"Instruct: Given a description, retrieve relevant songs\n Query: {query_description}"
).reshape(1, -1).astype(np.float32)
scores, temp_ids = temp_index.search(query_description_embedding, k)
final_song_ids = [top_k_indices[i] for i in temp_ids[0]]
return self.get_records_from_id(final_song_ids)
Voila! Finally, LyRec is ready. You can find the complete implementation on this repo. Please leave a star if you find this helpful! ????
GitHub - Suji04/LyRec: LyRec: Recommending Songs from User Query using LLMs
The Result ????
Using Lyrics
Now it’s time to see LyRec in action. For the first example, I’m taking Ed Sheeran’s Perfect ❤️. Here are the top few songs suggested by LyRec solely based on the lyrics. If you listen to these songs (which I highly recommend you do), you’ll find many similar elements to Perfect’s lyrics!https://medium.com/media/97894843921047d6ee4ae87a475eed46/hrefhttps://medium.com/media/89856ff3c4ab2170bd4979b5ee38943f/hrefhttps://medium.com/media/e1597bb92259b8628be3c7be66490c4d/href
Using Description
Let’s try the search by prompt feature. I gave LyRec this description.
Prompt: I want a dreamy, soft song about reminiscing on childhood memories, with a bittersweet feeling of nostalgia and the desire to return to simpler times.
LyRec obliged my request and returned the following. I think they are pretty good suggestions! Please listen for yourself.https://medium.com/media/b7116db8fae778caf6b5860fc79af216/hrefhttps://medium.com/media/b24180eda162f5f2bd886b38be05dec9/hrefhttps://medium.com/media/e0d2fbc1dd30d18261ef43d5bb004bc1/href
Using Lyrics + Description
Okay, so, finally, let’s try the last feature that allows both lyrics and description as input. My input to LyRec is the following.
Lyrics: Blinding Lights by The Weeknd
Prompt: I’m looking for an upbeat pop track that references nighttime energy.
Let’s see what LyRec has to offer this time.https://medium.com/media/8885eef21dddd644abbb89fa03e23748/hrefhttps://medium.com/media/818713c690aae19225984faf7c2eeca7/hrefhttps://medium.com/media/e6585d907c58fa8225a8b24406855837/href
I think these are pretty good suggestions! I’d highly encourage you to play with LyRec on your own. The embedding model is comparatively light-weight and can be run without expensive GPUs. I ran it on my M1 pro. I have included the lyrics dataset (with the generated summaries) and the embeddings in the repo.
The UI ✨
I don’t want to spend too much time talking about how I build the UI for LyRec as this is not the focus of this article. You can find the UI code on my repo. I am mentioning a few key points here.
- ChatGPT helped me create the web app!
- Tech stack: Flask, HTML, CSS
- For some reason, FAISS was not working on my Mac, so, I used another similar library called Annoy (by Spotify!) for the web app. Everything else is kept unchanged.
Here are a few screenshots. All images, unless otherwise mentioned, are by the author.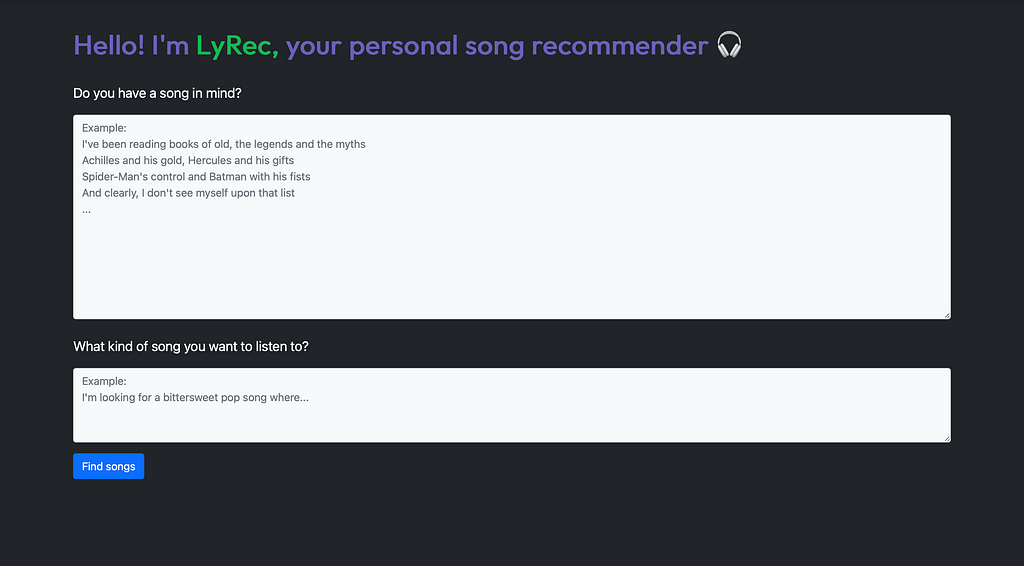
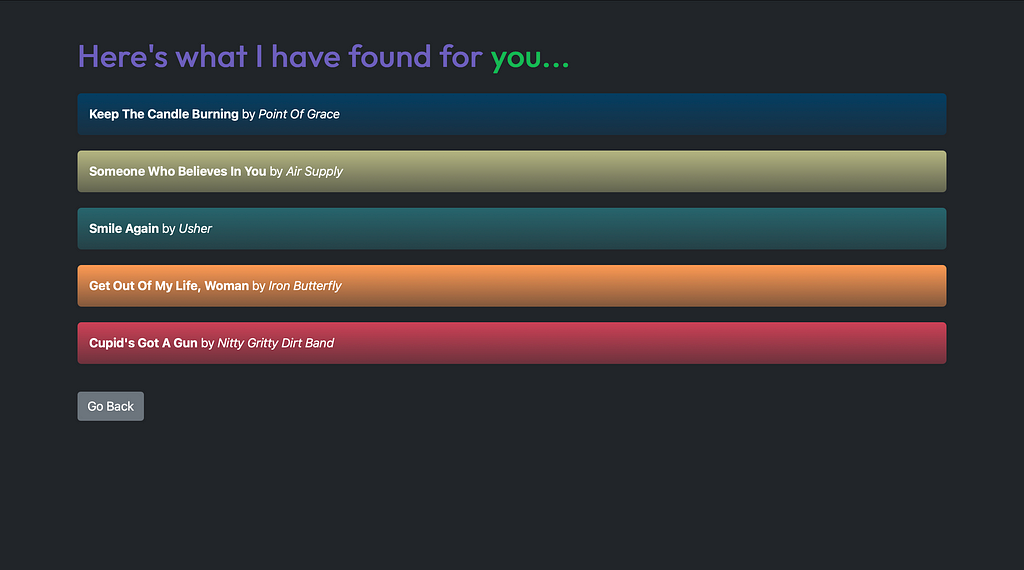
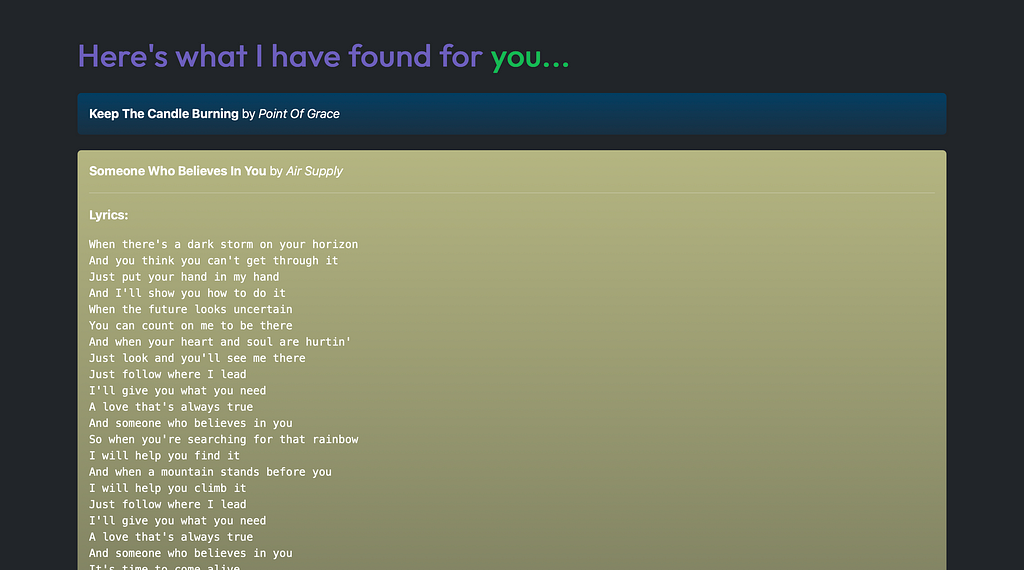
What’s Next? ⏭️
Now that I have shown you how LyRec works. Let’s talk about some of the limitations and possible improvements.
Song Popularity
While experimenting with LyRec, I realized it’d sometimes recommend songs that rarely attract any listeners. While it’s great for song (and artist) discovery, I guess popularity can be a helpful signal for quality. So, the final recommendation list may be sorted by song popularity to ensure robustness.
Song Metadata
Currently, LyRec uses only the lyrics, but songs are often associated with rich metadata, e.g., genre, tempo, key, valence score (Spotify), artist name, release date, etc. If included in the song summary, these features could improve the search and, hence, the recommendation.
Prompt Expansion
Let’s be honest, you don’t always want to write a detailed prompt for the text input. Here, we can use an LLM to write a better prompt from the sloppy user input and then use it as the query. This, in theory, should result in better retrieval.
That’s all I had for you today. I hope you enjoyed the reading. Until next time…Happy learning!
LyRec: A Song Recommender That Reads Between the Lyrics ???? was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.






