
KAIST and DeepAuto AI Researchers Propose InfiniteHiP: A Game-Changing Long-Context LLM Framework for 3M-Token Inference on a Single GPU
In large language models (LLMs), processing extended input sequences demands significant computational and memory resources, leading to slower inference and higher hardware costs. The attention mechanism, a core component, further exacerbates these challenges due to its quadratic complexity relative to sequence length. Also, maintaining the previous context using a key-value (KV) cache results in high […] The post KAIST and DeepAuto AI Researchers Propose InfiniteHiP: A Game-Changing Long-Context LLM Framework for 3M-Token Inference on a Single GPU appeared first on MarkTechPost.
 Editor-Admin
Editor-Admin



In large language models (LLMs), processing extended input sequences demands significant computational and memory resources, leading to slower inference and higher hardware costs. The attention mechanism, a core component, further exacerbates these challenges due to its quadratic complexity relative to sequence length. Also, maintaining the previous context using a key-value (KV) cache results in high memory overheads, limiting scalability.
A key limitation of LLMs is their inability to handle sequences longer than their trained context window. Most models degrade in performance when faced with extended inputs due to inefficient memory management and growing attention computation costs. Existing solutions often rely on fine-tuning, which is resource-intensive and requires high-quality long-context datasets. Without an efficient method for context extension, tasks like document summarization, retrieval-augmented generation, and long-form text generation remain constrained.
Several approaches have been proposed to tackle the problem of long-context processing. FlashAttention2 (FA2) optimizes memory consumption by minimizing redundant operations during attention computation, yet it does not address computational inefficiency. Some models employ selective token attention, either statically or dynamically, to reduce processing overhead. KV cache eviction strategies have been introduced to remove older tokens selectively, but they risk permanently discarding important contextual information. HiP Attention is another approach that attempts to offload infrequently used tokens to external memory; however, it lacks efficient cache management, leading to increased latency. Despite these advances, no method has effectively addressed all three key challenges:
- Long-context generalization
- Efficient memory management
- Computational efficiency
Researchers from the KAIST, and DeepAuto.ai introduced InfiniteHiP, an advanced framework that enables efficient long-context inference while mitigating memory bottlenecks. The model achieves this through a hierarchical token pruning algorithm, which dynamically removes less relevant context tokens. This modular pruning strategy selectively retains tokens that contribute the most to attention computations, significantly reducing processing overhead. The framework also incorporates adaptive RoPE (Rotary Positional Embeddings) adjustments, allowing models to generalize to longer sequences without additional training. Also, InfiniteHiP employs a novel KV cache offloading mechanism, transferring less frequently accessed tokens to host memory while ensuring efficient retrieval. These techniques enable the model to process up to 3 million tokens on a 48GB GPU, making it the most scalable long-context inference method.
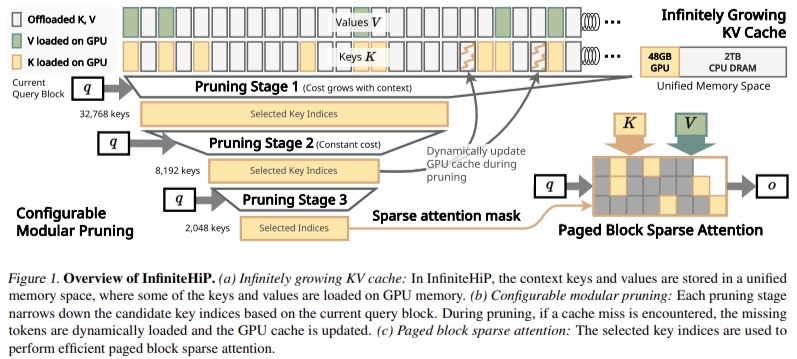
The core innovation of InfiniteHiP is its multi-stage pruning mechanism, which consistently improves context selection throughout multiple stages. Tokens are first divided into fixed-length pieces, and each piece is processed based on its attention computation contribution. A top-K selection approach ensures that only the most critical tokens are retained and others are dropped. The method followed by InfiniteHiP, unlike other hierarchical pruning models, is entirely parallelized, which renders it computationally effective. The KV cache management system optimizes memory utilization by dynamically offloading less important context tokens while maintaining retrieval flexibility. The model also utilizes multiple RoPE interpolation methods at different attention layers, thus facilitating smooth adaptation to long sequences.
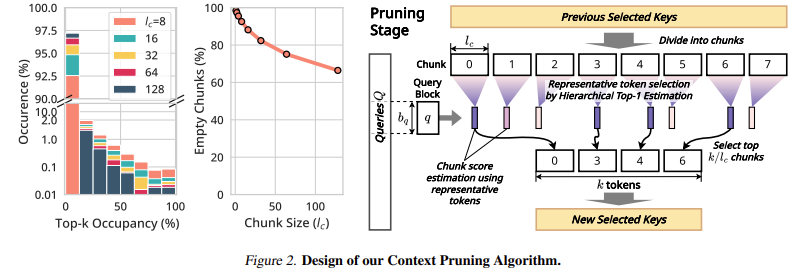
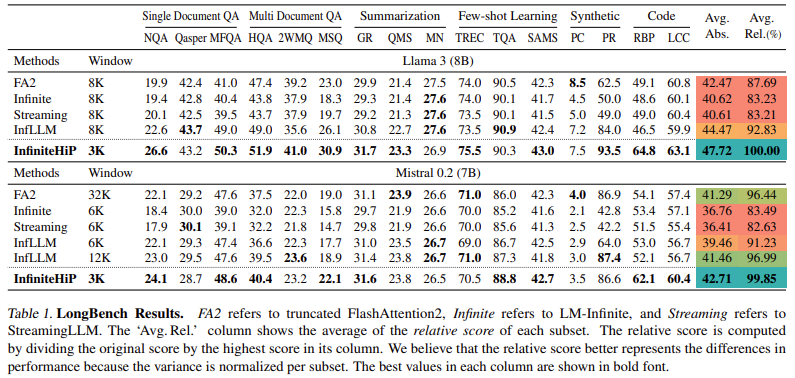
The model demonstrates an 18.95× speedup in attention decoding for a one million-token context compared to traditional methods without additional training. The KV cache offloading technique reduces GPU memory consumption by up to 96%, making it practical for large-scale applications. In benchmark evaluations such as LongBench and ∞Bench, InfiniteHiP consistently outperforms state-of-the-art methods, achieving a 9.99% higher relative score than InfLLM. Also, decoding throughput is increased by 3.2× on consumer GPUs (RTX 4090) and 7.25× on enterprise-grade GPUs (L40S).
In conclusion, the research team successfully addressed the major bottlenecks of long-context inference with InfiniteHiP. The framework enhances LLM capabilities by integrating hierarchical token pruning, KV cache offloading, and RoPE generalization. This breakthrough enables pre-trained models to process extended sequences without losing context or increasing computational costs. The method is scalable, hardware-efficient, and applicable to various AI applications requiring long-memory retention.
Check out the Paper, Source Code and Live Demo. All credit for this research goes to the researchers of this project. Also, feel free to follow us on Twitter and don’t forget to join our 75k+ ML SubReddit.
 Recommended Open-Source AI Platform: ‘IntellAgent is a An Open-Source Multi-Agent Framework to Evaluate Complex Conversational AI System’ (Promoted)
Recommended Open-Source AI Platform: ‘IntellAgent is a An Open-Source Multi-Agent Framework to Evaluate Complex Conversational AI System’ (Promoted)The post KAIST and DeepAuto AI Researchers Propose InfiniteHiP: A Game-Changing Long-Context LLM Framework for 3M-Token Inference on a Single GPU appeared first on MarkTechPost.






