
A Comprehensive Guide to Concepts in Fine-Tuning of Large Language Models (LLMs)
With the current conversation about widespread LLMs in AI, it is crucial to understand some of the basics involved. Despite their general-purpose pretraining in developing LLMs, most require fine-tuning to excel in specific tasks, domains, or applications. Fine-tuning tailors a model’s performance, making it efficient and precise for specialized use cases. Today, let’s examine the […] The post A Comprehensive Guide to Concepts in Fine-Tuning of Large Language Models (LLMs) appeared first on MarkTechPost.
 Editor-Admin
Editor-Admin



With the current conversation about widespread LLMs in AI, it is crucial to understand some of the basics involved. Despite their general-purpose pretraining in developing LLMs, most require fine-tuning to excel in specific tasks, domains, or applications. Fine-tuning tailors a model’s performance, making it efficient and precise for specialized use cases. Today, let’s examine the foundational concepts and advanced methodologies for fine-tuning LLMs.
Augmentation
Augmentation plays a central role in fine-tuning by extending the capabilities of LLMs by incorporating external data or techniques. This process equips models with the domain knowledge necessary to address specific challenges. For example, augmenting an LLM with legal terminology can significantly improve its performance in drafting contracts or summarizing case law. Augmentation ensures better contextual understanding, making outputs more relevant and reliable. However, augmentation comes with its challenges. Incorporating noisy or low-quality data can degrade model performance, emphasizing the need for robust data curation. Nevertheless, augmentation is a powerful tool for effectively enhancing model adaptability and precision.
Batch Size
Batch size refers to the count of samples processed before updating a model’s weights, a critical hyperparameter in fine-tuning. Small batch sizes allow for more frequent weight updates, which can help the model adapt quickly but might introduce noise into the learning process. Conversely, large batch sizes stabilize learning by smoothing gradient updates, but they can hinder the model’s ability to adapt to nuanced patterns. Striking the right balance in batch size ensures computational efficiency without compromising model performance. Fine-tuning practitioners often experiment with varying batch sizes to achieve optimal results, considering the trade-offs between learning speed and stability.
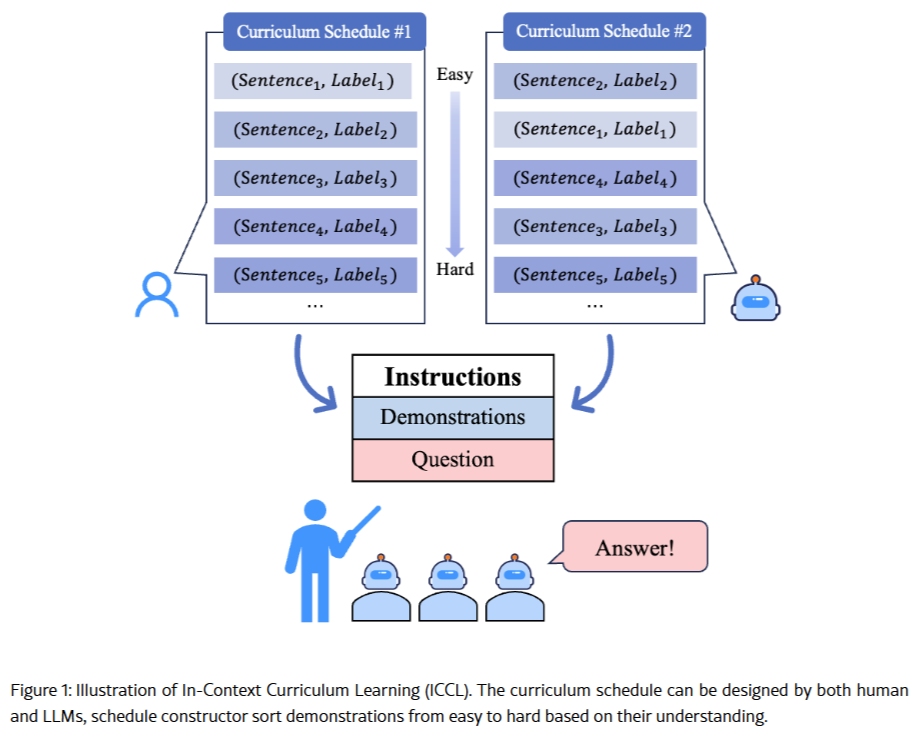
Curriculum Learning
Curriculum learning mimics the human learning process by gradually increasing the complexity of training data and tasks. This approach helps LLMs converge faster and generalize better across diverse tasks. For instance, when fine-tuning an LLM for customer service, the model might first be exposed to basic queries before handling complex multi-turn conversations. The gradual progression allows the model to build a strong foundation before tackling more intricate challenges. This method improves training efficiency and enhances the model’s robustness and ability to adapt to unseen scenarios.
Domain-Specific Tuning
Domain-specific fine-tuning tailors an LLM to meet the unique requirements of specialized fields, such as healthcare, finance, or law. This process involves training the model on high-quality, domain-specific datasets to ensure it understands the nuances of the targeted domain. For example, fine-tuning a general-purpose LLM on clinical data in the medical field enables it to assist with diagnostic suggestions or summarizing patient records. The key to successful domain-specific tuning lies in the quality and relevance of the training data. Poorly labeled or irrelevant data can lead to suboptimal performance, undermining the model’s effectiveness.
Embeddings
Embeddings are the numerical representations of text, enabling LLMs to understand semantic relationships between words and phrases. These dense numerical vectors power tasks like semantic search, clustering, and recommendations. Fine-tuning pipelines often leverage embeddings to refine the model’s contextual understanding. For example, embeddings can help a model distinguish between homonyms based on context, such as “bank” (a financial institution) versus “bank” (a riverbank). By refining embeddings during fine-tuning, models become adept at handling complex semantic relationships, enhancing their overall utility.
Few-Shot Learning
Few-shot learning demonstrates the adaptability of LLMs by allowing them to perform new tasks using minimal labeled data. This technique is particularly valuable when annotated datasets are scarce or expensive. For instance, a few examples of labeled customer reviews can enable an LLM to fine-tune itself for sentiment analysis. Few-shot learning balances the knowledge gained during pretraining with the requirements of the target task, making it an efficient and cost-effective fine-tuning approach.
Gradient Descent and Hyperparameter Optimization
Gradient descent, the backbone of training and fine-tuning LLMs, optimizes model performance by iteratively reducing the error between predictions and actual outputs. Alongside gradient descent, hyperparameters such as learning rate, batch size, and the number of epochs play a pivotal role in fine-tuning. Proper tuning of these hyperparameters can significantly impact the speed and accuracy of model training. For example, a poorly chosen learning rate can lead to underperformance or overfitting. Fine-tuning requires meticulous experimentation to identify the best hyperparameter configuration for a specific task.
Iterative Training
Iterative training involves repeated cycles of training and evaluation, allowing fine-tuned models to improve progressively. This step-by-step refinement is essential for achieving state-of-the-art performance. Each iteration fine-tunes the model’s weights, gradually reducing errors and enhancing generalization. This approach is effective when dealing with complex tasks, enabling practitioners to identify and address performance bottlenecks incrementally. By monitoring training metrics during iterations, overfitting risks can be minimized, ensuring robust model performance.
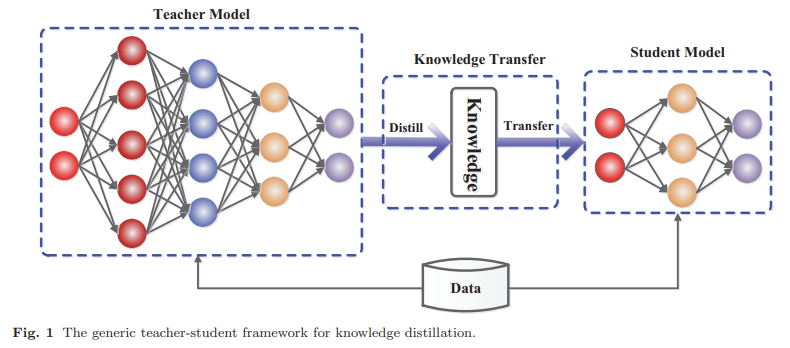
Knowledge Distillation
Knowledge distillation transfers the capabilities of larger, more complex models into smaller, more efficient ones. This technique is vital in resource-constrained environments with limited computational power and storage. For example, a compact version of an LLM can be deployed on mobile devices without sacrificing essential functionalities. Knowledge distillation retains the essence of the original model while reducing its size, making AI applications more accessible and scalable.
Pretraining and Fine-Tuning
Pretraining and fine-tuning are two complementary processes forming LLM development’s backbone. Pretraining provides a general knowledge base by exposing the model to massive, diverse datasets. Fine-tuning builds on this foundation, adapting the model to specific tasks or domains. This dual-phase process reduces the need for large task-specific datasets, as pretraining already equips the model with a broad understanding. For instance, an LLM pretrained on encyclopedic data can be fine-tuned on scientific papers to excel in technical writing.
Regularization and Validation
Regularization techniques like dropout, weight decay, and early stopping prevent overfitting during fine-tuning. These methods enhance the model’s ability to generalize to unseen data, ensuring reliability in real-world applications. Validation sets are equally critical. They provide an unbiased evaluation of the model’s performance during training, guide hyperparameter tuning, and help practitioners identify potential issues before deploying the model.
Tokenization and Noise Handling
Tokenization, breaking text into smaller units or tokens, prepares raw data for model consumption. Effective tokenization handles linguistic variations such as punctuation and casing, ensuring that the model processes text consistently. Handling noisy or low-quality data through robust preprocessing pipelines improves the model’s robustness. This step is crucial when working with real-world datasets, which often contain inconsistencies and errors.
Explainability and Yield Optimization
Explainability ensures transparency in LLM outputs, particularly important in high-stakes applications like healthcare or legal decision-making. Practitioners can identify biases and enhance trust in AI systems by understanding why a model produces specific predictions. Yield optimization focuses on refining the model to maximize its relevance and efficiency. This involves continuous monitoring and adjustments, ensuring the fine-tuned model delivers high-quality outputs in real-world scenarios.
Zero-Shot Learning
Zero-shot learning represents the cutting edge of LLM capabilities, enabling models to perform tasks without task-specific fine-tuning. By leveraging the general knowledge acquired during pretraining, LLMs can quickly adapt to new domains. This technique is a testament to the versatility and potential of advanced language models.
In conclusion, fine-tuning LLMs is a critical process that transforms general-purpose AI into specialized tools capable of addressing diverse challenges. By leveraging techniques like augmentation, curriculum learning, domain-specific tuning, and knowledge distillation, practitioners can tailor LLMs to excel in specific tasks. Despite challenges such as data scarcity and computational demands, innovations like zero-shot learning and iterative optimization continue to push the boundaries of LLM capabilities. Individuals, AI researchers, etc., need to have a good understanding of these concepts to explore LLMs
Sources
- https://arxiv.org/pdf/2402.10738v2
- https://arxiv.org/pdf/2006.05525
- https://arxiv.org/pdf/2011.08641
The post A Comprehensive Guide to Concepts in Fine-Tuning of Large Language Models (LLMs) appeared first on MarkTechPost.






