
Mixture-of-Denoising Experts (MoDE): A Novel Generalist MoE-based Diffusion Policy
Diffusion Policies in Imitation Learning (IL) can generate diverse agent behaviors, but as models grow in size and capability, their computational demands increase, leading to slower training and inference. This challenges real-time applications, especially in environments with limited computing power, like mobile robots. These policies need many parameters and denoising steps and, thus, are unsuitable […] The post Mixture-of-Denoising Experts (MoDE): A Novel Generalist MoE-based Diffusion Policy appeared first on MarkTechPost.
 Editor-Admin
Editor-Admin



Diffusion Policies in Imitation Learning (IL) can generate diverse agent behaviors, but as models grow in size and capability, their computational demands increase, leading to slower training and inference. This challenges real-time applications, especially in environments with limited computing power, like mobile robots. These policies need many parameters and denoising steps and, thus, are unsuitable for use in such scenarios. Although such models can be scaled with greater amounts of data, their large computational cost poses a significant limitation.
Current methods in robotics, such as Transformer-based Diffusion Models, are used for tasks like Imitation Learning, Offline Reinforcement Learning, and robot design. These models rely on Convolutional Neural Networks (CNNs) or transformers with conditioning techniques like FiLM. While capable of generating multimodal behavior, they are computationally expensive due to large parameters and many denoising steps, slowing training and inference, making them impractical for real-time applications. Additionally, Mixture-of-Experts (MoE) models face issues like expert collapse and inefficient capacity use. Despite load-balancing solutions, these models struggle to optimize the router and experts, leading to suboptimal performance.
To address the limitations of current methods, researchers from the Karlsruhe Institute of Technology and MIT introduced MoDE, a Mixture-of-Experts (MoE) Diffusion Policy designed for tasks such as Imitation Learning and robot design. MoDE improves efficiency by using noise-conditioned routing and a self-attention mechanism for more effective denoising at various noise levels. Unlike traditional methods that rely on a complex denoising process, MoDE computes and integrates only the necessary experts at each noise level, reducing latency and computational cost. This architecture enables faster and more efficient inference while maintaining performance, achieving significant computational savings by utilizing only a subset of the model’s parameters during each forward pass.
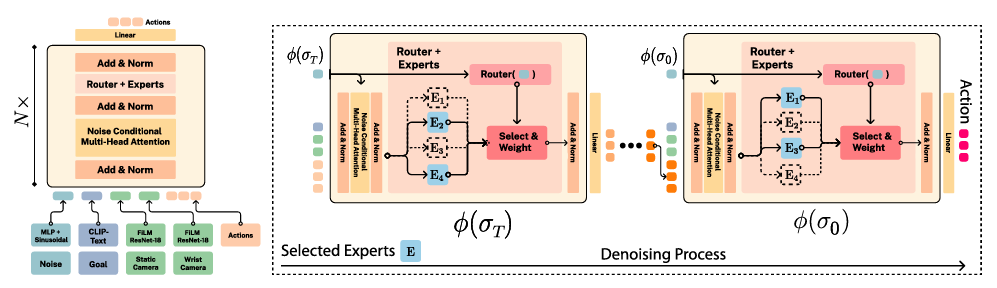
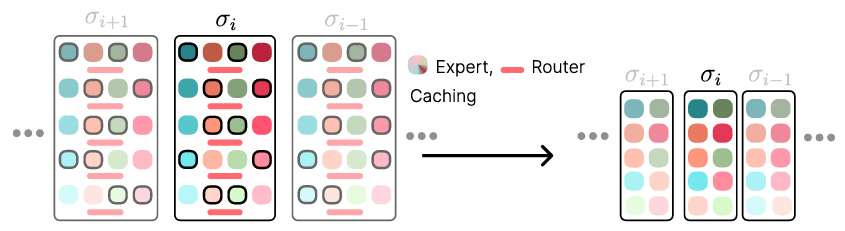
The MoDE framework employs a noise-conditioned approach where the routing of experts is determined by the noise level at each step. It uses a frozen CLIP language encoder for language conditioning and FiLM-conditioned ResNets for image encoding. The model incorporates a sequence of transformer blocks, each responsible for different denoising phases. By introducing noise-aware positional embeddings and expert caching, MoDE ensures that only the necessary experts are used, reducing computational overhead. The researchers conducted extensive analyses of MoDE’s components, which provide useful insights for designing efficient and scalable transformer architectures for diffusion policies. Pretraining on diverse multi-robot datasets allows MoDE to outperform existing generalist policies.
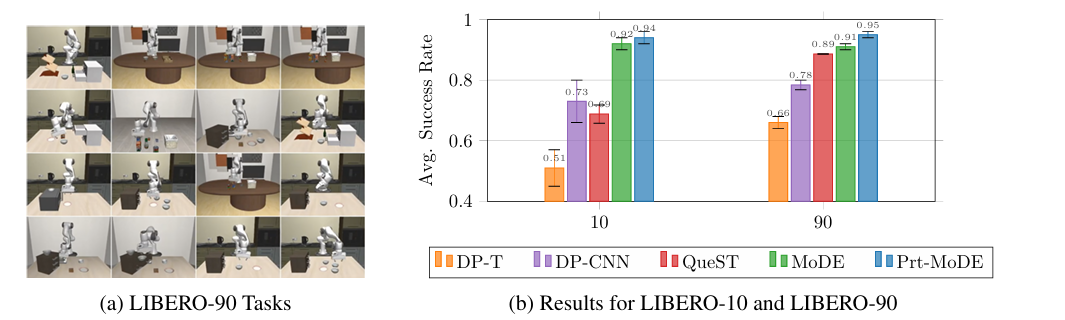
Researchers conducted experiments to evaluate MoDE on several key questions, including its performance compared to other policies and diffusion transformer architectures, the effect of large-scale pretraining on its performance, efficiency, and speed, and the effectiveness of token routing strategies in different environments. The experiments compared MoDE with prior diffusion transformer architectures, ensuring fairness by using a similar number of active parameters, and tested it on both long-horizon and short-horizon tasks. MoDE achieved the highest performance in benchmarks such as LIBERO–90, outperforming other models like Diffusion Transformer and QueST. Pretraining MoDE boosted its performance, demonstrating its ability to learn long-horizon tasks and its efficiency in computational use. MoDE also showed superior performance on the CALVIN Language-Skills Benchmark, surpassing models like RoboFlamingo and GR-1 while maintaining higher computational efficiency. MoDE outperformed all baselines in zero-shot generalization tasks and demonstrated strong generalization capabilities.
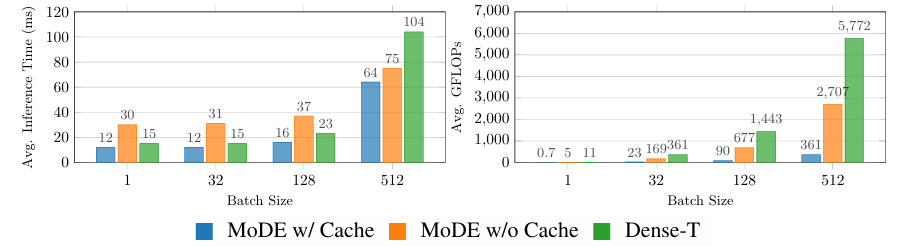
In conclusion, the proposed framework improves performance and efficiency using a combination of experts, a Transformer, and a noise-conditioned routing strategy. The model outperformed previous Diffusion Policies, requiring fewer parameters and reduced computational costs. Therefore, this framework can be used as a baseline to improve the model’s scalability in future research studies. Future studies can also discuss the application of MoDE across other domains because it has thus far been possible to continue scaling up while maintaining high-performance levels in machine learning tasks.
Check out the Paper and Model on Hugging Face. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t Forget to join our 60k+ ML SubReddit.
 FREE UPCOMING AI WEBINAR (JAN 15, 2025): Boost LLM Accuracy with Synthetic Data and Evaluation Intelligence–Join this webinar to gain actionable insights into boosting LLM model performance and accuracy while safeguarding data privacy.
FREE UPCOMING AI WEBINAR (JAN 15, 2025): Boost LLM Accuracy with Synthetic Data and Evaluation Intelligence–Join this webinar to gain actionable insights into boosting LLM model performance and accuracy while safeguarding data privacy.
The post Mixture-of-Denoising Experts (MoDE): A Novel Generalist MoE-based Diffusion Policy appeared first on MarkTechPost.






