
Mastering Sensor Fusion: Color Image Obstacle Detection with KITTI Data — Part 2
Mastering Sensor Fusion: Color Image Obstacle Detection with KITTI Data — Part 2How to use color image data for object detection in the context of obstacle detectionThe concept of sensor fusion is a decision-making mechanism that can be applied to different problems and using different modalities. We mentioned in the previous post that in this Medium blog series, we will analyze the concept of sensor fusion for obstacle detection with both Lidar and color images. If you haven’t read that post yet, which is related to obstacle detection with Lidar data, here is the link to it:Sensor Fusion — KITTI — ‘Lidar-based Obstacle Detection’ — Part-1This post is a continuation, and in this section, I will get deep into the obstacle detection problem on color images. In the next and last post of the series (I hope it will be available soon!), we will be investigating sensor fusion using both Lidar and color images.But before moving on to this step, let’s continue with our uni-modality-based study. Just as we previously performed obstacle detection using only Lidar data, here we will perform obstacle detection using only color images.As we did in the first post, we will use the KITTI dataset here again. For information about which data needs to be downloaded from KITTI [1], please check the previous post. There it was stated which data, labels, and calibration files are required for each data type.However, for those who do not have much time, we are analyzing the 3D Object Detection problem within the scope of the KITTI Vision Benchmark Suite. In this context, we will work on color images obtained with the “left camera” throughout this post.The first of the subheadings we will examine within the scope of this post is the analysis of images obtained with the “left camera”. The next topic will be the 2D image-based object detectors. While these object detectors have a long history and different types like two-stage detectors, single-stage detectors, or Vision-Language Models, we will be analyzing the most popular two techniques: YoloWorld [2], which is an open vocabulary object detector and YoloV8[3], which is a single-stage object detector. In this context, before comparing these object detectors, I will be giving applied examples of how to fine-tune YoloV8 for the KITTI Object detection problem. Afterward, we will compare the models, and yes, we will complete this post by talking about the slice-aided object detection framework, SAHI [4], to solve the problem of detecting small-sized objects that we will see in the future.So let’s start with the data analysis part!2D Colored Image Dataset Analysis of KITTIThe KITTI 3D Object Detection dataset includes 7481 training and 7581 testing images. And, each training image has a label file that includes the object coordinates in the image plane. These label files are presented in “.txt” format and are organized line-based. And, each row represents the labeled objects in the relevant image. In this context, each row consists of a total of 16 columns (If you are interested in these columns, I highly recommend you take a look at the previous article in this series). But to put it roughly here, the first column indicates the type of the relevant object, and the values between the 5th and 8th columns indicate the location of that object in the image coordinate system. Let me share a sample image and its label file as follows.A sample 2D colored image (Image taken from KITTI)The corresponding label file of above image (Label file taken fom KITTI)As we can see a lot of cars and three pedestrians are identified in the image. Before getting into the deeper analysis, let me share the object types in KITTI. KITTI has 9 different classes in label files. These are, “Car”, “Truck”, “Van”, “Tram”, “Pedestrian”, “Cyclist”, “Person_sitting”, “Misc”, and “DontCare”.While some object types are obvious, “Misc” and “Don’t Care” may seem a little bit confusing. Meanwhile, “Misc” stands for objects that do not fit into the main categories above (Car, pedestrian, cyclist, etc.). They could be traffic cones, small objects, unknown vehicles, or objects that resemble objects but cannot be clearly classified. On the other hand, “DontCare” refers to regions that we should not take into consideration.After getting informed about the classes, let’s try to visualize the distribution of the main classes.The distribution of main classes in KITTI colored imagesAs can be seen from the distribution graph, there is an unbalanced distribution in terms of the number of examples contained in the classes. For example, while the number of examples in the “Car” class is much higher than the average number of examples in the classes, the situation is exactly the opposite for the “Person_sitting” class.Here I would like to open a parenthesis about these numbers, especially from a statistical learning perspective. Such unbalanced distributions among classes may cause statistical learning methods to underperform or be biased
 Editor-Admin
Editor-Admin

Mastering Sensor Fusion: Color Image Obstacle Detection with KITTI Data — Part 2
How to use color image data for object detection in the context of obstacle detection
The concept of sensor fusion is a decision-making mechanism that can be applied to different problems and using different modalities. We mentioned in the previous post that in this Medium blog series, we will analyze the concept of sensor fusion for obstacle detection with both Lidar and color images. If you haven’t read that post yet, which is related to obstacle detection with Lidar data, here is the link to it:
Sensor Fusion — KITTI — ‘Lidar-based Obstacle Detection’ — Part-1
This post is a continuation, and in this section, I will get deep into the obstacle detection problem on color images. In the next and last post of the series (I hope it will be available soon!), we will be investigating sensor fusion using both Lidar and color images.
But before moving on to this step, let’s continue with our uni-modality-based study. Just as we previously performed obstacle detection using only Lidar data, here we will perform obstacle detection using only color images.
As we did in the first post, we will use the KITTI dataset here again. For information about which data needs to be downloaded from KITTI [1], please check the previous post. There it was stated which data, labels, and calibration files are required for each data type.
However, for those who do not have much time, we are analyzing the 3D Object Detection problem within the scope of the KITTI Vision Benchmark Suite. In this context, we will work on color images obtained with the “left camera” throughout this post.
The first of the subheadings we will examine within the scope of this post is the analysis of images obtained with the “left camera”. The next topic will be the 2D image-based object detectors. While these object detectors have a long history and different types like two-stage detectors, single-stage detectors, or Vision-Language Models, we will be analyzing the most popular two techniques: YoloWorld [2], which is an open vocabulary object detector and YoloV8[3], which is a single-stage object detector. In this context, before comparing these object detectors, I will be giving applied examples of how to fine-tune YoloV8 for the KITTI Object detection problem. Afterward, we will compare the models, and yes, we will complete this post by talking about the slice-aided object detection framework, SAHI [4], to solve the problem of detecting small-sized objects that we will see in the future.
So let’s start with the data analysis part!
2D Colored Image Dataset Analysis of KITTI
The KITTI 3D Object Detection dataset includes 7481 training and 7581 testing images. And, each training image has a label file that includes the object coordinates in the image plane. These label files are presented in “.txt” format and are organized line-based. And, each row represents the labeled objects in the relevant image. In this context, each row consists of a total of 16 columns (If you are interested in these columns, I highly recommend you take a look at the previous article in this series). But to put it roughly here, the first column indicates the type of the relevant object, and the values between the 5th and 8th columns indicate the location of that object in the image coordinate system. Let me share a sample image and its label file as follows.

As we can see a lot of cars and three pedestrians are identified in the image. Before getting into the deeper analysis, let me share the object types in KITTI. KITTI has 9 different classes in label files. These are, “Car”, “Truck”, “Van”, “Tram”, “Pedestrian”, “Cyclist”, “Person_sitting”, “Misc”, and “DontCare”.
While some object types are obvious, “Misc” and “Don’t Care” may seem a little bit confusing. Meanwhile, “Misc” stands for objects that do not fit into the main categories above (Car, pedestrian, cyclist, etc.). They could be traffic cones, small objects, unknown vehicles, or objects that resemble objects but cannot be clearly classified. On the other hand, “DontCare” refers to regions that we should not take into consideration.
After getting informed about the classes, let’s try to visualize the distribution of the main classes.
As can be seen from the distribution graph, there is an unbalanced distribution in terms of the number of examples contained in the classes. For example, while the number of examples in the “Car” class is much higher than the average number of examples in the classes, the situation is exactly the opposite for the “Person_sitting” class.
Here I would like to open a parenthesis about these numbers, especially from a statistical learning perspective. Such unbalanced distributions among classes may cause statistical learning methods to underperform or be biased toward some classes. I would like to leave some important keywords that should come to mind in such a situation for readers who want to deal with this subject: sub-sampling, regularization, bias-variance problem, weighted or focal loss, etc. (If you would like a post from me about these concepts, please leave it in the comments.)
Another topic we will investigate in the analysis section will be related to the size of the objects. By size here, I mean the dimensions of the relevant objects in pixels in the image coordinate system. This issue may be overlooked at first, or it may not be understood what kind of positive return measuring this may have. However, the average bounding box size of a certain object type may be inherently much smaller than the box size of other object classes. In this case, we either cannot detect that object type (which happens most of the time) or we can classify it as a different object type (rarely). Then let’s analyze the size distribution of each class as follows.
If we keep the “Misc” and “DontCare” object types separate, there is a marginal difference between the bounding box sizes of the “Pedestrian”, “Person_sitting” and “Cyclist” types and the sizes of the other object types. This gives us a red flag that we may need to make a special effort when identifying these classes. In this context, I will give you some tips in the following sections by opening a special subheading on slicing-aided object detection!
2D Image-based Object Detector
2D image-based object detectors are computer vision models designed to identify and locate objects within images. These models can be broadly categorized into two-stage and single-stage detectors. In two-stage detectors, the model first generates potential object proposals through a region proposal network (RPN) or similar mechanisms. Then, in the second stage, these proposals are refined and classified into specific object categories. A popular example of this type is Faster R-CNN [5]. This approach is known for its high accuracy as it performs a detailed evaluation of potential objects, but it tends to be slower due to the two-step process, which can be a limitation for real-time applications.
In contrast, single-stage detectors aim to detect objects in a single pass by directly predicting both object locations and classifications for all potential bounding boxes. This approach is faster and more efficient, making it ideal for real-time detection applications. Examples include YOLO (You Only Look Once)[3] and SSD (Single Shot Multibox Detector)[6]. These models divide the image into a grid and predict bounding boxes and class probabilities for each grid cell, resulting in a more streamlined and faster detection process. Although single-stage detectors may trade off some accuracy for speed, they are widely used in applications requiring real-time performance, such as autonomous driving and video surveillance.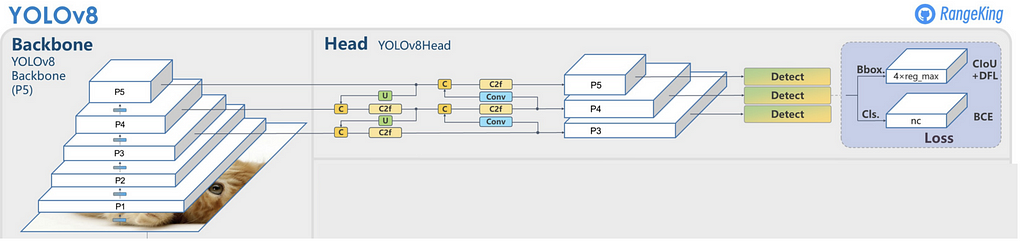
After the introductory information is given let’s dive into to object detectors that are applied to our problem; the first one is YoloWorld[2] and the second one is YoloV8 [3]. Here you may wonder why we are analyzing two different Yolo models. The main point here is that YoloV8 is a single-stage detector, while YoloWorld is a special type of detector that has been studied a lot in recent years with an open keyword, that is, no close set classification model. And it means that, in theory, these models, which are Open Vocabulary Detection-based ones, are capable of detecting any kind of object!
YoloWorld
YoloWorld is one of the promising studies in the open-vocabulary object detection era. But what exactly is open-vocabulary object detection?
To understand the concept of the open-vocabulary, let’s take a step back and understand the core idea behind traditional object detectors. Sample and simple cornerstones of training a model can be presented as follows.
In traditional machine learning, a model is trained on n different classes, and its performance is evaluated only on those n classes. For example, let's consider a class that wasn’t included during training, such as "Bird." If we give an image of a bird to the trained model, it will not be able to detect the “Bird” in the image. Since the "Bird" is not part of the training dataset, the model cannot recognize it as a new class or generalize to understand that it’s something outside its training. In short, traditional models cannot identify or handle classes they haven’t seen during training.
On the other hand, open-vocabulary object detection overcomes this limitation by enabling models to detect objects beyond the classes they were explicitly trained on. This is achieved by leveraging visual-text representations, where models are trained with paired image-text data, such as “a photo of a cat” or “a person riding a bicycle.” Instead of relying solely on fixed class labels, these models learn a more general understanding of objects through their semantic descriptions.
As a result, when presented with a new object class, like “Bird,” the model can recognize and classify it by associating the visual features of the object with the textual descriptions, even if the class was not part of its training data. This capability is particularly useful in real-world applications where the variety of objects is vast, and it’s impractical to train models on every possible category.
So how does this mechanism work? In fact, the real magic here is the use of visual and textual information together. So let’s first see the system architecture of YoloWorld and then analyze the core components one by one.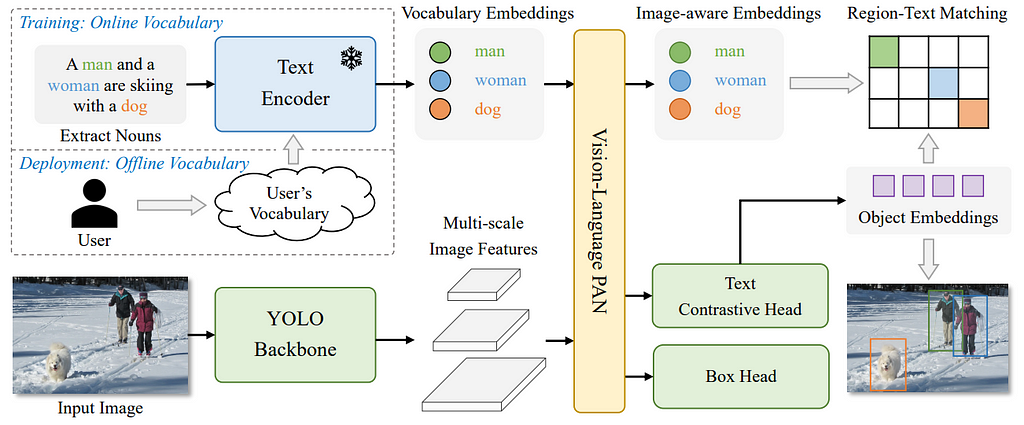
We can analyze the model from general to specific as follows. YoloWorld takes Image {I} and the corresponding texts {T} as input then outputs predicted Bounding Boxes {Bk} and Object Embeddings {ek}.
{T} is fed into to pre-trained CLIP [7] model to be converted into vocabulary embeddings. On the other hand, YOLO Backbone, which is a visual information encoder, takes {I} and extracts multi-scale image features. Right now, two different input types have their own modality-specific embeddings, processed by different encoders. However, “Vision-Language PAN” takes both embeddings and creates a kind of multimodality embeddings using a cross-modality fusion approach.
Let’s go over this layer step-by-step. First {Cx} are the multi-scale visual features. On the top, we have textual embeddings {Tc}. Each visual feature follows the Cx ∈ H×W×D dimension and each textual feature follows the Tc ∈ CXD dimension. Then multiplication of each component (after reshaping of visual features), there will be an attention score vector, which is formed 1XC.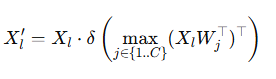
Then by normalizing the maximum attention vector and multiplying the visual vector and fusion-based attention vector, we calculate the new form of visual vector.
Then these newly formed visual features are fed into the “I-Pooling Attention” layer, which employs the 3x3 max kernels to extract 27 patches. The output of these patches is given to the Multi-Head_Attention mechanism, which is similar to the Transformer arch., to update Image-aware textual embeddings as follows.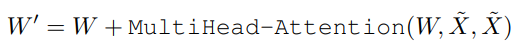
After these processes, the outputs are formed by two regression heads. The first one is the “Text Contrastive Head” and the other one is the “Bounding Box Head”. The overall system loss function, to train the model, can be presented as follows.
Then, now let’s get into the applied section to see the results WITHOUT doing any fine-tuning. After all, we expect this model to make correct determinations even if it is not trained specifically with our KITTI classes, right ????
As we did in our previous blog post, you can find the complete files, codes, etc. by following the GitHub link, which I provide at the bottom.
The first step is model initialization, and defining our classes, which are interested in the KITTI problem.
# Load YOLOOpenWorld model (pre-trained on COCO dataset)
yoloWorld_model = YOLOWorld("yolov8x-worldv2.pt")
# Define class names to filter
target_classes = ["car", "van", "truck", "pedestrian", "person_sitting", "cyclist", "tram"]
class_map = {idx:class_name for idx, class_name in enumerate(target_classes)}
## set the interested classes there
yoloWorld_model.set_classes(target_classes)
The next step is loading a sample image and its G.T. box visualization.
The G.T. bounding boxes for our sample are as follows. More specifically, the G.T. label includes, 9 cars and 3 pedestrians! (such a complex scene)
Before getting into the YoloWorld prediction, let me reiterate that we did not make any fine-tuning to the YoloWorld model, we took the model as is. The prediction with it can be done as follows.
## 2. Perform detection and detection list arrangement
det_boxes, det_class_ids, det_scores = utils.perform_detection_and_nms(yoloWorld_model, sample_image, det_conf= 0.35, nms_thresh= 0.25)
The output of the prediction is as follows.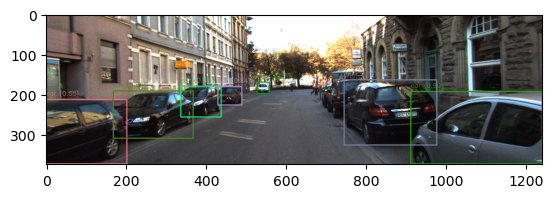
Regarding the prediction, we can see that there are 6 cars class and 1 van class found. The evaluation of the output can be done as follows.
## 4. Evaluate the predicted detections with G.T. detections
print("# predicted boxes: {}".format(len(pred_detections)))
print("# G.T. boxes: {}".format(len(gt_detections)))
tp, fp, fn, tp_boxes, fp_boxes, fn_boxes = utils.evaluate_detections(pred_detections, gt_detections, iou_threshold=0.40)
pred_precision, pred_recall = utils.calculate_precision_recall(tp, fp, fn)
print(f"TP: {tp}, FP: {fp}, FN: {fn}")
print(f"Precision: {pred_precision}, Recall: {pred_recall}")

Now as we can, 1 object is identified but misclassified (the actual class is “Car” but classified as “Van”). Then in total, 6 boxes couldn’t be found. Then it makes our recall score 0.5 and precision score ~0.86.
Let me share some other predicted figures with you as examples.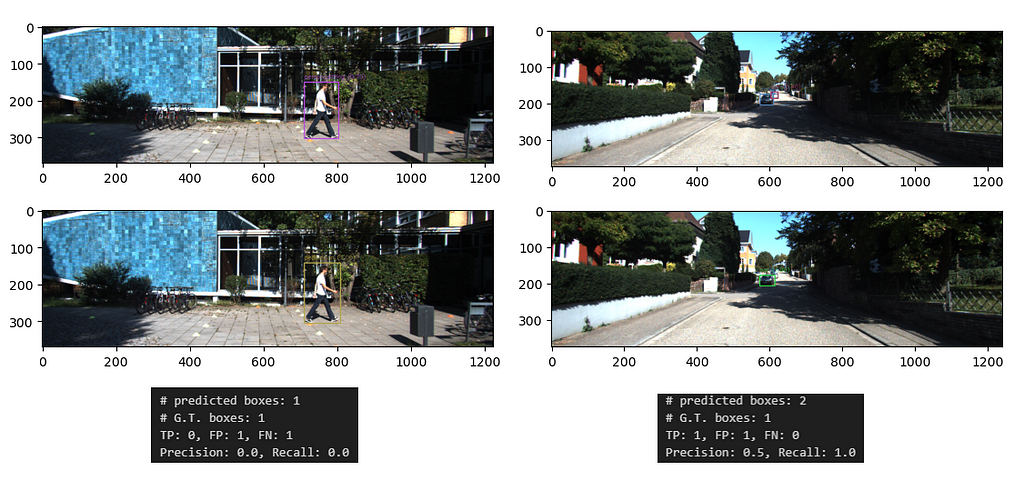
While the first row refers to the predicted samples, the second one represents the G.T. boxes and classes. On the left side, we can see a pedestrian who walks from left to right. Fortunately, YoloWorld predicted the object perfectly in terms of bounding box dimensions, but the class is predicted as “Pedestrian_sitting” while the G.T. label is “Pedestrian”. This is why precision and recall are both 0.0 :/
On the right side, YoloWorld predicts 2 “Cars” while G.T. has only 1 “Car”. For this reason, the precision score is 0.5 and the recall score is 1.0
So for now, we have seen a couple of Yolo predictions, and the model can be somehow acceptable as an initial step, can’t it?
We have to admit that an improvement is definitely needed for the model with such a critical application area. However, it should not be forgotten that we were able to achieve some adequate results even without fine-tuning here!
And then that requirement leads us to our next step, which is the traditional model, the YoloV8, and the fine-tuning of it. Let’s go!
YoloV8
YOLOv8 (You Only Look Once version 8) is the one of most advanced versions in the YOLO family of object detection models, designed to push the boundaries of speed, accuracy, and flexibility in computer vision tasks. Building on the success of its predecessors, YOLOv8 integrates innovative features such as anchor-free detection mechanisms and decoupled detection heads to streamline the object detection pipeline. These enhancements reduce computational overhead while improving the detection of objects across varying scales and complex scenarios. Moreover, YOLOv8 introduces dynamic task adaptability, allowing it to perform not just object detection but also image segmentation and classification seamlessly. This versatility makes it a go-to solution for diverse real-world applications, from autonomous vehicles and surveillance to medical imaging and retail analytics.
What sets YOLOv8 apart is its focus on modern deep learning trends, such as optimized training pipelines, state-of-the-art loss functions, and model scaling strategies. The inclusion of anchor-free detection eliminates the need for predefined anchor boxes, making the model more robust to varying object shapes and reducing the chances of false negatives. The decoupled head design separately optimizes classification and regression tasks, improving overall detection accuracy. In addition, YOLOv8’s lightweight architecture ensures faster inference times without compromising on performance, making it suitable for deployment on edge devices. Overall, YOLOv8 continues the YOLO legacy by providing a highly efficient and accurate solution for a wide range of computer vision tasks.
For more in-depth analysis and implementation details, refer to:
- Yolov8 Medium post: https://docs.ultralytics.com/
- An exploration article: https://arxiv.org/pdf/2408.15857
But before getting into the next step, where we’re going to fine-tune the Yolo model for our problem, let’s visualize the output of the off-the-shelf YoloV8 model on our sample image. (Of course, the off-the-shelf model doesn’t cover all the classes of our problem, but at least it can detect the cars and pedestrians that we need for our sample image)
## Load the off-the-shelf yolo model and get the class name mapping dict
off_the_shelf_model = YOLO("yolov8m.pt")
off_the_shelf_class_names = off_the_shelf_model.names
## then make a prediction as we did before
det_boxes, det_class_ids, det_scores = utils.perform_detection_and_nms(off_the_shelf_model, sample_image, det_conf= 0.35, nms_thresh= 0.25)

The off-the-shelf model predicts 8 cars, which is almost okay! Only 1 car and 1 pedestrian are missing, but that is also okay for now.
Then let’s try to fine-tune that off-the-shelf model to adapt it to our problem.
YoloV8 Fine-Tuning
In this section, we will fine-tune the off-the-shelf YoloV8-m model to fit our problem well. But before that, we need to adjust the proper label files. I know it’s not the funniest part, but it’s a mandatory thing to do before seeing the progress bar in the fine-tuning stage. To make it available, I prepared the following function, which is available in my Github repo like all other components.
def convert_label_format(label_path, image_path, class_names=None):
"""
Converts a custom label format into YOLO label format.
This function takes a path to a label file and the corresponding image file, processes the label information,
and outputs the annotations in YOLO format. YOLO format represents bounding boxes with normalized values
relative to the image dimensions and includes a class ID.
Key Parameters:
- `label_path` (str): Path to the label file in custom format.
- `image_path` (str): Path to the corresponding image file.
- `class_names` (list or set, optional): A collection of class names. If not provided,
the function will create a set of unique class names encountered in the labels.
Processing Details:
1. Reads the image dimensions to normalize bounding box coordinates.
2. Filters out labels that do not match predefined classes (e.g., car, pedestrian, etc.).
3. Converts bounding box coordinates from the custom format to YOLO's normalized center-x, center-y, width, and height format.
4. Updates or utilizes the provided `class_names` to assign a class ID for each annotation.
Returns:
- `yolo_lines` (list): List of strings, each in YOLO format ().
- `class_names` (set or list): Updated set or list of unique class names.
Notes:
- The function assumes specific indices (4 to 7) for bounding box coordinates in the input label file.
- Normalization is based on the dimensions of the input image.
- Class filtering is limited to a predefined set of relevant classes.
"""
A sample label file after this operation will look as follows.
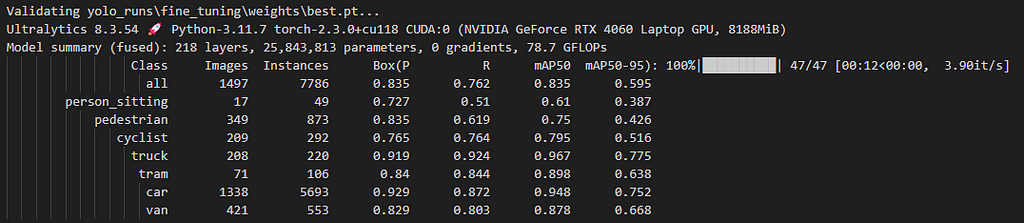
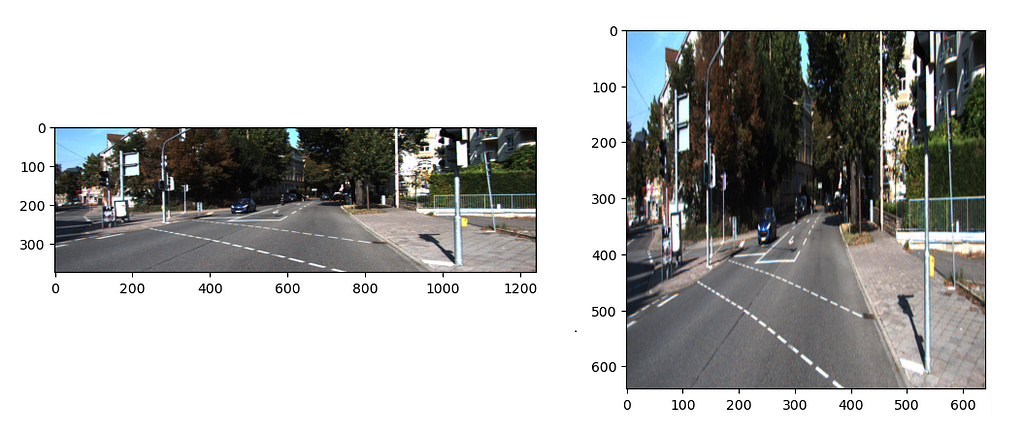
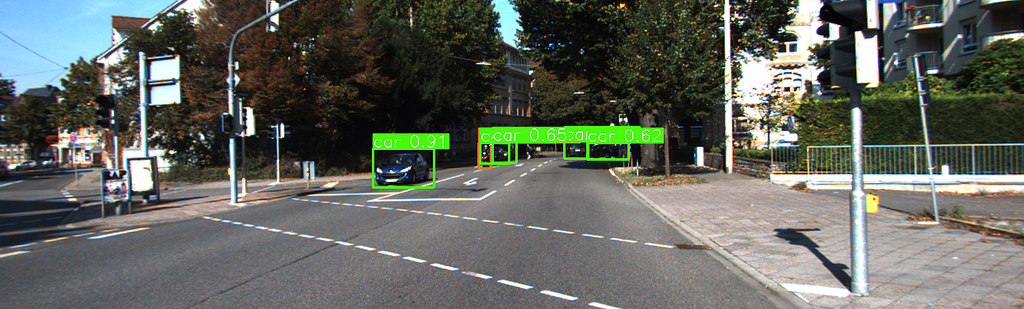
The first Then, it’s time to fine-tune our model! In that stage, I used to default fine-tuning parameters, which are defined here: https://docs.ultralytics.com/models/yolov8/#can-i-benchmark-yolov8-models-for-performance But I HIGHLY encourage you to try other hyper-parameters like learning rate, optimizer, etc. Since those parameters directly affect the output performance of the model, they are so crucial. Anyway, let’s try to keep it simple for now, and jump into the output performance of our fine-tuned model for KITTI’s main classes. As we can see, the overall mAP50 is 0.835, which is good for the first shoot. But the “Person_sitting” and “Pedestrian” classes, which are important ones in autonomous driving do not hit, show 0.61 and 0.75 mAP50 scores. There could be some reasons behind it; their bounding box dimensions are relatively smaller than the others and the other reason could be the number of samples of these classes. Of course, there are some others like “Cyclist” and “Tram” that have a couple of images too, but yeah it’s kind of a black box. If you want me to investigate this behavior in deep, please indicate it in the comments. It would be a pleasure for me! As we did in the previous sections let me share the result of the sample image again for the fine-tuned model here. Now, the fine-tuned model detected 2 pedestrians, 1 cyclist, 9 cars! It’s almost done for that sample image. Cause this detection means that; It’s much better than the off-the-shelf model (even if we haven’t done too much hyper-parameter searching!). Then let me share another image with you. Now, in that scene, there is a car on the left side. But wait! There are some others around there, but they are too small to see. Let’s check our fancy fine-tuned model output! OMG! It only detects the car and a cyclist who is right behind it. How about the others who are staying right of the cyclist? Yeah, now this situation takes us to our next and final topic: detecting small-sized objects in the 2D image. Let’s go. KITTI images have 1342 pixels on the width and 375 pixels on the height side. Then applying them a resizing operation just before feeding to the model, makes them 640 by 640. Let me show you a visual that is right before feeding to the model as follows. We can see that some objects are severely distorted. In addition, we can observe that some objects farther from the camera become even smaller. There is a method that we can use to overcome the problems experienced in both these types of situations and in detecting objects in very high-resolution images. And its name is “SAHI” [4], Slicing Aided Hyper Inference. Its core concept is so clear; it divides images into smaller, manageable slices, performs object detection on each slice, and merges the results seamlessly. However, running the object detection model repeatedly on multiple slices and combining the results would, as can be expected, require significant computational power and time. However, SAHI is able to overcome this with its optimizations and memory usage! In addition, its compatibility with many different object detectors makes it suitable for practical work. Here are some links to understand SAHI in depth and observe its performance enhancements for different problems: — SAHI Paper: https://arxiv.org/pdf/2202.06934 — SAHI GitHub: https://github.com/obss/sahi Then let’s visualize our second sample image with SAHI-based inference: Wow! We can see that several cars and a cyclist are found perfectly! If you also face the same kind of problem like this, please check the paper and the implementation! Well, now we have finally come to the end. During this process, we first tried to solve Lidar-based obstacle detection with an unsupervised learning algorithm in our first article. In this article, we used different object detection algorithms. Among these, the “open-vocabulary” based YoloWorld, or the more traditional “close-set” object detection model YoloV8, and the “fine-tuned” version of YoloV8, which is more suitable for the KITTI problem. In addition, we obtained some results with the help of “SAHI” regarding the detection of small-sized objects. Of course, each topic we mentioned is an active research area. And many researchers are still trying to achieve more successful results in these areas. Here, we tried to produce solutions from the perspective of the applied scientist. However, if there is a topic you want me to talk about more or if you want a completely different article about some parts, please indicate this in the comments. Then, for now, let’s meet in the next publication, which will be the last article of the series, where we will detect obstacles with both Lidar and color images using both sensors at the same time. ******************************************************************************************************************************************************** GitHub link: https://github.com/ErolCitak/KITTI-Sensor-Fusion/tree/main/color_image_based_object_detection References: [1] https://www.cvlibs.net/datasets/kitti/ [2] https://docs.ultralytics.com/models/yolo-world/ [3] https://docs.ultralytics.com/models/yolov8/ [4] https://github.com/obss/sahi [5] https://arxiv.org/abs/1506.01497 [6] https://arxiv.org/abs/1512.02325 [7] https://openai.com/index/clip/ The images used in this blog series are taken from the KITTI dataset for education and research purposes. If you want to use it for similar purposes, you must go to the relevant website, approve the intended use there, and use the citations defined by the benchmark creators as follows. For the stereo 2012, flow 2012, odometry, object detection, or tracking benchmarks, please cite: For the raw dataset, please cite: For the road benchmark, please cite: For the stereo 2015, flow 2015, and scene flow 2015 benchmarks, please cite: Mastering Sensor Fusion: Color Image Obstacle Detection with KITTI Data — Part 2 was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story. def create_data_yaml(images_path, labels_path, base_path, train_ratio=0.8):
"""
Creates a dataset directory structure with train and validation splits for YOLO format.
This function organizes image and label files into separate training and validation directories,
converts label files to the YOLO format, and ensures the output structure adheres to YOLO conventions.
Key Parameters:
- `images_path` (str): Path to the directory containing the image files.
- `labels_path` (str): Path to the directory containing the label files in custom format.
- `base_path` (str): Base directory where the train/val split directories will be created.
- `train_ratio` (float, optional): Ratio of images to allocate for training (default is 0.8).
Processing Details:
1. **Dataset Splitting**:
- Reads all image files from `images_path` and splits them into training and validation sets
based on `train_ratio`.
2. **Directory Creation**:
- Creates the necessary directory structure for train/val splits, including `images` and `labels` subdirectories.
3. **Label Conversion**:
- Uses `convert_label_format` to convert label files to YOLO format.
- Updates a set of unique class names encountered in the labels.
4. **File Organization**:
- Copies image files into their respective directories (train or val).
- Writes the converted YOLO labels into the appropriate `labels` subdirectory.
Returns:
- None (operates directly on the file system to organize the dataset).
Notes:
- The function assumes labels correspond to image files with the same name (except for the file extension).
- Handles label conversion using a predefined set of class names, ensuring consistency.
- Uses `shutil.copy` for images to avoid removing original files.
Dependencies:
- Requires `convert_label_format` to be implemented for proper label conversion.
- Relies on `os`, `shutil`, `Path`, and `tqdm` libraries.
Usage Example:
```python
create_data_yaml(
images_path='/path/to/images',
labels_path='/path/to/labels',
base_path='/output/dataset',
train_ratio=0.8
)
"""def train_yolo_world(data_yaml_path, epochs=100):
"""
Trains a YOLOv8 model on a custom dataset.
This function leverages the YOLOv8 framework to fine-tune a pretrained model using a specified dataset
and training configuration.
Key Parameters:
- `data_yaml_path` (str): Path to the YAML file containing dataset configuration (e.g., paths to train/val splits, class names).
- `epochs` (int, optional): Number of training epochs (default is 100).
Processing Details:
1. **Model Initialization**:
- Loads the YOLOv8 medium-sized model (`yolov8m.pt`) as a base model for training.
2. **Training Configuration**:
- Defines training hyperparameters including image size, batch size, device, number of workers, and early stopping (`patience`).
- Results are saved to a project directory (`yolo_runs`) with a specific run name (`fine_tuning`).
3. **Training Execution**:
- Initiates the training process and tracks metrics such as loss and mAP.
Returns:
- `results`: Training results, including metrics for evaluation and performance tracking.
Notes:
- Assumes that the YOLOv8 framework is properly installed and accessible via `YOLO`.
- The dataset YAML file must include paths to the training and validation datasets, as well as class names.
Dependencies:
- Requires the `YOLO` class from the YOLOv8 framework.
Usage Example:
```python
results = train_yolo_world(
data_yaml_path='path/to/data.yaml',
epochs=50
)
print(results)
"""




Dealing with Small-sized Objects
Conclusion
What’s next?
Any comments, error fixes, or improvements are welcome!
Thank you all and I wish you healthy days.
Disclaimer
@inproceedings{Geiger2012CVPR,
author = {Andreas Geiger and Philip Lenz and Raquel Urtasun},
title = {Are we ready for Autonomous Driving? The KITTI Vision Benchmark Suite},
booktitle = {Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2012}
}
@article{Geiger2013IJRR,
author = {Andreas Geiger and Philip Lenz and Christoph Stiller and Raquel Urtasun},
title = {Vision meets Robotics: The KITTI Dataset},
journal = {International Journal of Robotics Research (IJRR)},
year = {2013}
}
@inproceedings{Fritsch2013ITSC,
author = {Jannik Fritsch and Tobias Kuehnl and Andreas Geiger},
title = {A New Performance Measure and Evaluation Benchmark for Road Detection Algorithms},
booktitle = {International Conference on Intelligent Transportation Systems (ITSC)},
year = {2013}
}
@inproceedings{Menze2015CVPR,
author = {Moritz Menze and Andreas Geiger},
title = {Object Scene Flow for Autonomous Vehicles},
booktitle = {Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2015}
}






