
Large Language Models: A Short Introduction
And why you should care about LLMsImage by author.There’s an acronym you’ve probably heard non-stop for the past few years: LLM, which stands for Large Language Model.In this article we’re going to take a brief look at what LLMs are, why they’re an extremely exciting piece of technology, why they matter to you and me, and why you should care about LLMs.Note: in this article, we’ll use Large Language Model, LLM and model interchangeably.What is an LLMA Large Language Model, typically referred to as LLM since it is a bit of a tongue twister, is a mathematical model that generates text, like filling in the gap for the next word in a sentence [1].For instance, when you feed it the sentence The quick brown fox jumps over the lazy ____, it doesn’t know exactly that the next word is dog. What the model produces instead is a list of possible next words with their corresponding probability of coming next in a sentence that starts with those exact words.Example of prediction of the next word in a sentence. Image by author.The reason why LLMs are so good at predicting the next word in a sentence is because they are trained with an incredibly large amount of text, which typically is scraped from the Internet. So if a model is ingesting the text in this article by any chance, Hi ????On the other hand, if you’re building an LLM that is specific to a particular domain, for example, you’re building a chatbot that could converse with you as if they were a character in Shakespeare’s plays, the internet will for sure have a lot of snippets or even his complete works, but it will have a ton of other text that’s not relevant to the task at hand. In this case, you would feed the LLM on the chatbot only Shakespeare context, i.e., all of his plays and sonnets.Although LLMs are trained with a gigantic amount of data, that’s not what the Large in Large Language Models stands for. Besides the size of the training data, the other large quantity in these models is the number of parameters they have, each one with the possibility of being adjusted, i.e., tuned.The simplest statistical models is Simple Linear Regression, with only two parameters, the slope and the intercept. And even with just two parameters, there are a few different shapes the model output can take.Different shapes of a linear regression. Image by author.As a comparison, when GPT-3 was released in 2020 it had 175B parameters, yes Billion![3] While LLaMa, Meta’s open source LLM, had a number of different models ranging from 7B to 65B parameters when it was released in 2023.These billions of parameters all start with random values, at the beginning of the training process, and it’s during the Backpropagation part of the training phase that they continually get tweaked and adjusted.Similar to any other Machine Learning model, during the training phase, the output of the model is compared with the actual expected value for the output, in order to calculate the error. When there’s still room for improvement, Backpropagation ensures the model parameters are adjusted such that the model can predict values with a little bit less error the next time.But this is just what’s called pre-training, where the model becomes proficient at predicting the next word in a sentence.In order for the model to have really good interactions with a human, to the point that you — the human — can ask the chatbot a question and its response seems structurally accurate, the underlying LLM has to go through a step of Reinforcement Learning with Human Feedback. This is literally the human in the loop that is often talked about in the context of Machine Learning models.In this phase, humans tag predictions that are not as good and by taking in that feedback, model parameters are updated and the model is trained again, as many times needed, to reach the level of prediction quality desired.It’s clear by now that these models are extremely complex, and need to be able to perform millions, if not billions of computations. This high-intensity compute required novel architectures, at the model level with Transformers and for compute, with GPUs.GPU is this class of graphic processors used in scenarios when you need to perform an incredibly big number of computations in a short period of time, for instance while smoothly rendering characters in a videogame. Compared to the traditional CPUs found in your laptop or tower PC, GPUs have the ability to effortlessly run many parallel computations.The breakthrough for LLMs was when researchers realized GPUs can also be applied to non graphical problems. Both Machine Learning and Computer Graphics rely on linear algebra, running operations on matrices, so both benefit from the ability to execute many parallel computations.Transformers is a new type of architecture developed by Google, which makes it such that each operation done during model training can be parallelized. For instance, while predicting the next word in a sentence, a model that uses a Transformer archit
 Editor-Admin
Editor-Admin

And why you should care about LLMs

There’s an acronym you’ve probably heard non-stop for the past few years: LLM, which stands for Large Language Model.
In this article we’re going to take a brief look at what LLMs are, why they’re an extremely exciting piece of technology, why they matter to you and me, and why you should care about LLMs.
Note: in this article, we’ll use Large Language Model, LLM and model interchangeably.
What is an LLM
A Large Language Model, typically referred to as LLM since it is a bit of a tongue twister, is a mathematical model that generates text, like filling in the gap for the next word in a sentence [1].
For instance, when you feed it the sentence The quick brown fox jumps over the lazy ____, it doesn’t know exactly that the next word is dog. What the model produces instead is a list of possible next words with their corresponding probability of coming next in a sentence that starts with those exact words.
The reason why LLMs are so good at predicting the next word in a sentence is because they are trained with an incredibly large amount of text, which typically is scraped from the Internet. So if a model is ingesting the text in this article by any chance, Hi ????
On the other hand, if you’re building an LLM that is specific to a particular domain, for example, you’re building a chatbot that could converse with you as if they were a character in Shakespeare’s plays, the internet will for sure have a lot of snippets or even his complete works, but it will have a ton of other text that’s not relevant to the task at hand. In this case, you would feed the LLM on the chatbot only Shakespeare context, i.e., all of his plays and sonnets.
Although LLMs are trained with a gigantic amount of data, that’s not what the Large in Large Language Models stands for. Besides the size of the training data, the other large quantity in these models is the number of parameters they have, each one with the possibility of being adjusted, i.e., tuned.
The simplest statistical models is Simple Linear Regression, with only two parameters, the slope and the intercept. And even with just two parameters, there are a few different shapes the model output can take.
As a comparison, when GPT-3 was released in 2020 it had 175B parameters, yes Billion![3] While LLaMa, Meta’s open source LLM, had a number of different models ranging from 7B to 65B parameters when it was released in 2023.
These billions of parameters all start with random values, at the beginning of the training process, and it’s during the Backpropagation part of the training phase that they continually get tweaked and adjusted.
Similar to any other Machine Learning model, during the training phase, the output of the model is compared with the actual expected value for the output, in order to calculate the error. When there’s still room for improvement, Backpropagation ensures the model parameters are adjusted such that the model can predict values with a little bit less error the next time.
But this is just what’s called pre-training, where the model becomes proficient at predicting the next word in a sentence.
In order for the model to have really good interactions with a human, to the point that you — the human — can ask the chatbot a question and its response seems structurally accurate, the underlying LLM has to go through a step of Reinforcement Learning with Human Feedback. This is literally the human in the loop that is often talked about in the context of Machine Learning models.
In this phase, humans tag predictions that are not as good and by taking in that feedback, model parameters are updated and the model is trained again, as many times needed, to reach the level of prediction quality desired.
It’s clear by now that these models are extremely complex, and need to be able to perform millions, if not billions of computations. This high-intensity compute required novel architectures, at the model level with Transformers and for compute, with GPUs.
GPU is this class of graphic processors used in scenarios when you need to perform an incredibly big number of computations in a short period of time, for instance while smoothly rendering characters in a videogame. Compared to the traditional CPUs found in your laptop or tower PC, GPUs have the ability to effortlessly run many parallel computations.
The breakthrough for LLMs was when researchers realized GPUs can also be applied to non graphical problems. Both Machine Learning and Computer Graphics rely on linear algebra, running operations on matrices, so both benefit from the ability to execute many parallel computations.
Transformers is a new type of architecture developed by Google, which makes it such that each operation done during model training can be parallelized. For instance, while predicting the next word in a sentence, a model that uses a Transformer architecture doesn’t need to read the sentence from start to end, it process the entire text all at the same time, in parallel. It associates each word processed with a long array of numbers that give meaning to that word. Thinking about Linear Algebra again for a second, instead of processing and transforming one data point at a time, the combo of Transformers and GPUs can process tons of points at the same time by leveraging matrices.
In addition to parallelized computation, what distinguishes Transformers is an unique operation called Attention. In a very simplistic way, Attention makes it possible to look at all the context around a word, even if it occurs multiple times in different sentences like
At the end of the show, the singer took a bow multiple times.
Jack wanted to go to the store to buy a new bow for target practice.
If we focus on the word bow, you can see how the context in which this word shows up in each sentence and its actual meaning are very different.
Attention allows the model to refine the meaning each word encodes based on the context around them.
This, plus some additional steps like training a Feedforward Neural Network, all done multiple times, make it such that the model gradually refines its capacity to encode the right information. All these steps are intended to make the model more accurate and not mix up the meaning of bow, the motion, and bow (object related to archery) when it runs a prediction task.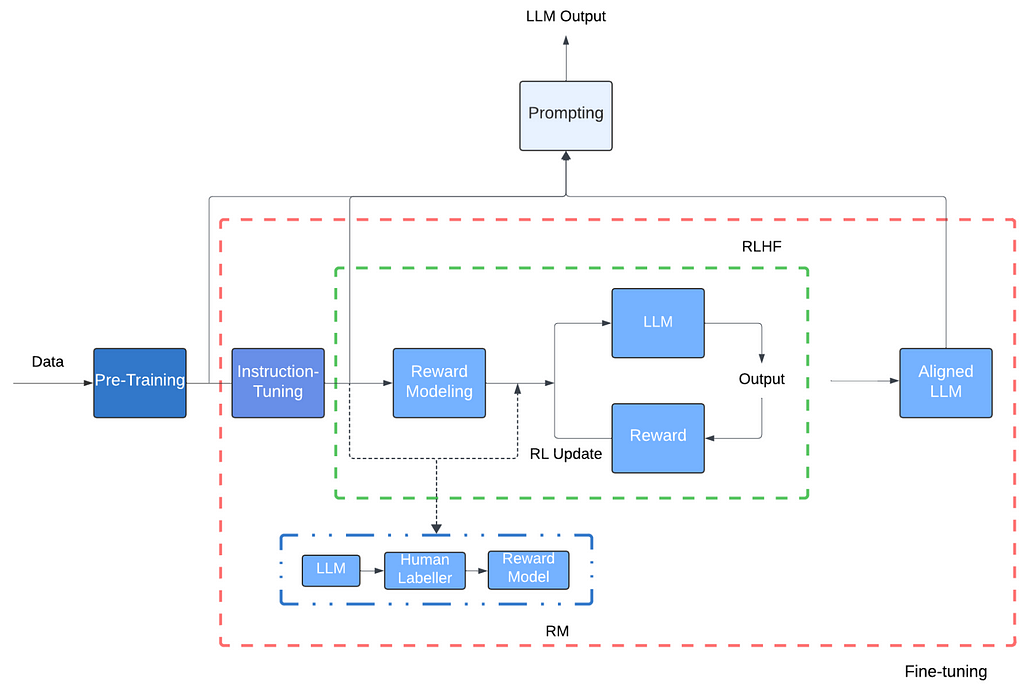
The development of Transformers and GPUs allowed LLMs to explode in usage and application compared to prior to language models that needed to read one word at a time. Knowing that a model gets better the more quality data it learns from, you can see how processing one word at a time was a huge bottleneck.
Why LLMs Matter
With the capacity described, that LLMs can process enormous amounts of text examples and then predict with a high accuracy, the next word in a sentence, combined with other powerful Artificial Intelligence frameworks, many natural language and information retrieval tasks that became much easier to implement and productize.
In essence, Large Language Models (LLMs) have emerged as cutting edge artificial intelligence systems that can process and generate text with coherent communication and generalize multiple tasks[2].
Think about tasks like translating from English to Spanish, summarizing a set of documents, identifying certain passages in documents, or having a chatbot answer your questions about a particular topic.
These tasks that were possible before, but the effort required to build a model was incredibly higher and the rate of improvement of these models was much slower due to technology bottlenecks. LLMs came in and supercharged all of these tasks and applications.
You’ve probably interacted or seen someone interacting directly with products that use LLMs at their core.
These products are much more than a simple LLM that accurately predicts the next word in a sentence. They leverage LLMs and other Machine Learning techniques and frameworks, to understand what you’re asking, search through all the contextual information they’ve seen so far, and present you with a human-like and, most times coherent, answer. Or at least some provide guidance about what to look into next.
There are tons of Artificial Intelligence (AI) products that leverage LLMs, from Facebook’s Meta AI, Google’s Gemini, Open AI’s ChatGPT, which borrows its name from the Generative Pre-trained Transformer technology under the hood, Microsoft’s CoPilot, among many, many others, covering a wide range of tasks to assist you on.
For instance, a few weeks ago, I was wondering how many studio albums Incubus had released. Six months ago, I’d probably Google it or go straight to Wikipedia. Nowadays, I tend to ask Gemini.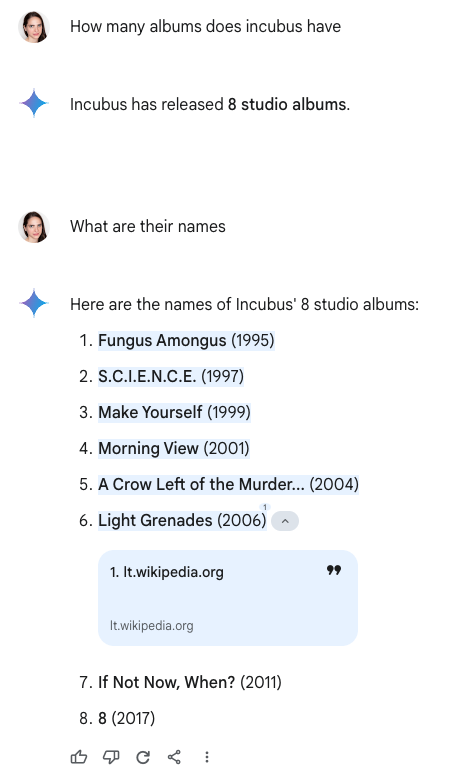
This is only a simplistic example. There are many other types of questions or prompts you can provide to these Artificial Intelligence products, like asking to summarize a particular text or document, or if you’re like me and you’re traveling to Melbourne, asking for recommendations about what to do there.
It cut straight to the point, provided me with a variety of pointers on what to do, and then I was off to the races, able to dig a bit further on specific places that seemed more interesting to me.
You can see how this saved me a bunch of time that I would probably have to spend between Yelp an TripAdvisor reviews, Youtube videos or blogposts about iconic and recommended places in Melbourne.
Conclusion
LMMs are, without a doubt, a nascent area of research that has been evolving at a lightning fast pace, as you can see by the timeline below.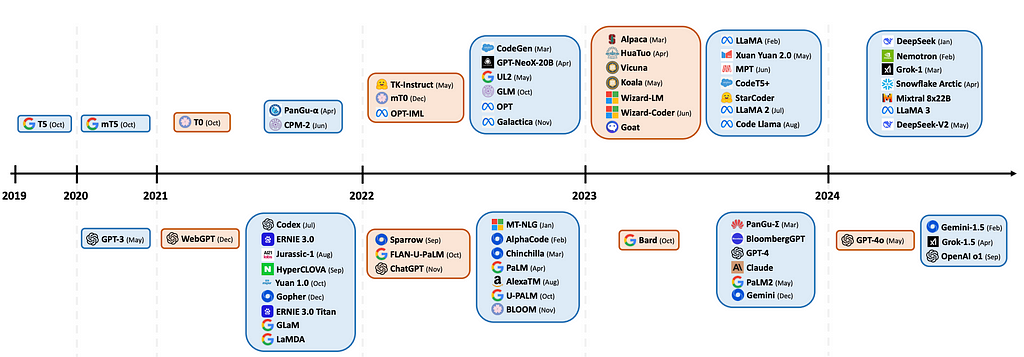
We’re just in the very early days of productization, or product application. More and more companies are applying LLMs to their domain areas, in order to streamline tasks that would take them several years, and an incredible amount of funds to research, develop and bring to market.
When applied in ethical and consumer-conscious ways, LLMs and products that have LLMs at their core provide a massive opportunity to everyone. For researchers, it’s a cutting edge field with a wealth of both theoretical and practical problems to untangle.
For example, in Genomics, gLMs or Genomic Language Models, i.e., Large Language Models trained on DNA sequences, are used to accelerate our general understanding of genomes and how DNA works and interacts with other functions[4]. These are big questions for which scientists don’t have definitive answers for, but LLMs are proving to be a tool that can help them make progress at a much bigger scale and iterate on their findings much faster. To make steady progress in science, fast feedback loops are crucial.
For companies, there’s a monumental shift and opportunity to do more for customers, address more of their problems and pain-points, making it easier for customers to see the value in products. Be it for effectiveness, ease of use, cost, or all of the above.
For consumers, we get to experience products and tools to assist us on day-to-day tasks, that help perform our our jobs a little better, to gain faster access to knowledge or get pointers to where we can search and dig deeper for that information.
To me, the most exciting part, is the speed at which these products evolve and outdate themselves. I’m personally curious to see how these products will look like in the next 5 years and how they can become more accurate and reliable.
Technological leaps and scientific breakthroughs used to take decades or even centuries to occur. So it’s nothing shy of rational to be apprehensive when we experience big technological step-changes multiple times during our lifetime.
Among all the hype and some of the fads that come and go, the core technology underlying Large Language Models is fascinating and has proven to have interesting and plausible applications.
Hope you enjoyed this brief overview of LLMs, why they matter, and why it’s worth continuing to keep an eye on this research area and new AI products.
Thanks for reading!
References
[1] Large Language Models explained briefly (video)
[2] A Comprehensive Overview of Large Language Models. 2024.Humza Naveed and Asad Ullah Khan and Shi Qiu and Muhammad Saqib and Saeed Anwar and Muhammad Usman and Naveed Akhtar and Nick Barnes and Ajmal Mian.
[3] Language Models are Few-Shot Learners. 2020. Tom B. Brown and Benjamin Mann and Nick Ryder and Melanie Subbiah and Jared Kaplan and Prafulla Dhariwal and Arvind Neelakantan and Pranav Shyam and Girish Sastry and Amanda Askell and Sandhini Agarwal and Ariel Herbert-Voss and Gretchen Krueger and Tom Henighan and Rewon Child and Aditya Ramesh and Daniel M. Ziegler and Jeffrey Wu and Clemens Winter and Christopher Hesse and Mark Chen and Eric Sigler and Mateusz Litwin and Scott Gray and Benjamin Chess and Jack Clark and Christopher Berner and Sam McCandlish and Alec Radford and Ilya Sutskever and Dario Amodei
[4]Genomic Language Models: Opportunities and Challenges. 2024. Gonzalo Benegas and Chengzhong Ye and Carlos Albors and Jianan Canal Li and Yun S. Song.
Large Language Models: A Short Introduction was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.






