
Google AI Introduces Iterative BC-Max: A New Machine Learning Technique that Reduces the Size of Compiled Binary Files by Optimizing Inlining Decisions
When applying Reinforcement Learning (RL) to real-world applications, two key challenges are often faced during this process. Firstly, the constant online interaction and update cycle in RL places major engineering demands on large systems designed to work with static ML models needing only occasional offline updates. Secondly, RL algorithms usually start from scratch, relying solely […] The post Google AI Introduces Iterative BC-Max: A New Machine Learning Technique that Reduces the Size of Compiled Binary Files by Optimizing Inlining Decisions appeared first on MarkTechPost.
 Editor-Admin
Editor-Admin



When applying Reinforcement Learning (RL) to real-world applications, two key challenges are often faced during this process. Firstly, the constant online interaction and update cycle in RL places major engineering demands on large systems designed to work with static ML models needing only occasional offline updates. Secondly, RL algorithms usually start from scratch, relying solely on information gathered during these interactions, limiting both their efficiency and adaptability. In common situations where RL is applied, there are usually earlier efforts using rule-based or supervised ML methods that produce a lot of useful data about good and bad behaviors. Ignoring this information leads to inefficient learning in RL from the beginning.
Current methods in Reinforcement Learning involve an online interaction-then-update cycle, which can be inefficient for large-scale systems. These approaches include overlooking valuable, already available data from rule-based or supervised machine-learning methods and learning from scratch. Many RL methods rely on value function estimation and require access to Markov Decision Process (MDP) dynamics, often employing Q-learning techniques with per-timestep rewards for accurate credit assignment. However, these methods depend on dense rewards and function approximators, making them unsuitable for offline RL scenarios with aggregated reward signals. To address this, researchers have proposed an imitation learning-based algorithm that integrates trajectories from multiple baseline policies to create a new policy that exceeds the performance of the best combination of these baselines. This approach reduces sample complexity and increases performance by manipulating existing data.
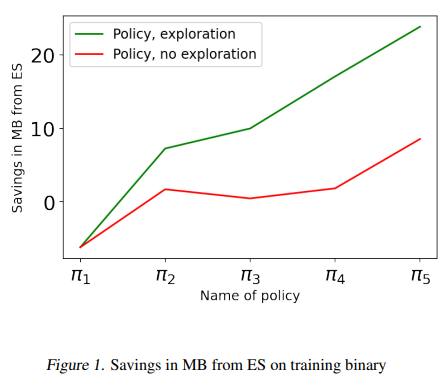
A group of researchers from Google AI have proposed a method involving collecting trajectories from K baseline policies, each excelling in different parts of the state space. The paper addresses a Contextual Markov Decision Process (MDP) with finite horizons, where each baseline policy has context-dependent deterministic transitions and rewards. Given baseline policies and trajectory data, the goal is to identify a policy from a given class that competes with the best-performing baseline for each context. This involves offline imitation learning with sparse trajectory-level rewards, complicating traditional methods reliant on value function approximation. The proposed BC-MAX algorithm chooses the trajectory with the highest cumulative reward per context and clones it, focusing on matching optimal action sequences. Unlike methods requiring access to detailed state transitions or value functions, BC-MAX operates under limited reward data, optimizing a cross-entropy loss as a proxy to direct policy learning. The paper provides theoretical regret bounds for BC-MAX, ensuring performance close to the best baseline policy for each context.
In this, the limitation learning algorithm combines trajectories to learn a new policy. The researchers provide a sample complexity bound on the algorithm’s accuracy and prove its minimax optimality. They apply this algorithm to compiler optimization, specifically for inlining programs to create smaller binaries. The results showed that the new policy outperforms an initial policy learned via standard RL after a few iterations. It introduces BC-MAX, a behavior cloning algorithm designed to optimize performance by executing multiple policies across initial states and imitating the trajectory with the highest reward in each state. The authors provide an upper bound on the expected regret of the learned policy relative to the maximum achievable reward in each starting state by selecting the best baseline policy. The analysis includes a lower bound, demonstrating that further improvement is limited to polylogarithmic factors in this context. Applied to two real-world datasets for optimizing compiler inlining for binary size, BC-MAX outperforms strong baseline policies. Starting with a single online RL-trained policy, BC-MAX iteratively incorporates previous policies as baselines, achieving robust policies with limited environmental interaction. This approach shows significant potential for challenging real-world applications.
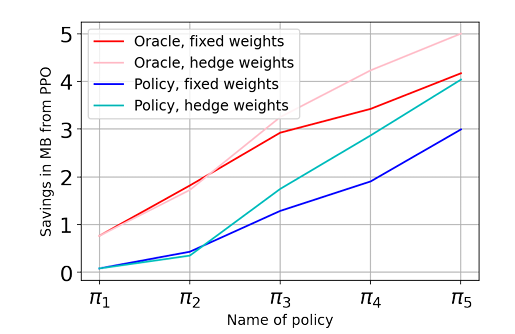
In conclusion, the paper presents a novel offline imitation learning algorithm, BC-MAX, which effectively leverages multiple baseline policies to optimize compiler inlining decisions. The method addresses the limitations of current RL approaches by utilizing prior data and minimizing the need for online updates by leveraging multiple baselines, proposing a novel imitation learning algorithm that improves performance and reduces sample complexity, particularly in compiler optimization tasks. It also demonstrated that a policy can be learned that outperforms an initial policy learned via standard RL through a few iterations of our approach. This research can serve as a baseline for future development in RL!
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 55k+ ML SubReddit.
[Upcoming Live Webinar- Oct 29, 2024] The Best Platform for Serving Fine-Tuned Models: Predibase Inference Engine (Promoted)
The post Google AI Introduces Iterative BC-Max: A New Machine Learning Technique that Reduces the Size of Compiled Binary Files by Optimizing Inlining Decisions appeared first on MarkTechPost.






