
BEAL: A Bayesian Deep Active Learning Method for Efficient Deep Multi-Label Text Classification
Multi-label text classification (MLTC) assigns multiple relevant labels to a text. While deep learning models have achieved state-of-the-art results in this area, they require large amounts of labeled data, which is costly and time-consuming. Active learning helps optimize this process by selecting the most informative unlabeled samples for annotation, reducing the labeling effort. However, most […] The post BEAL: A Bayesian Deep Active Learning Method for Efficient Deep Multi-Label Text Classification appeared first on MarkTechPost.
 Editor-Admin
Editor-Admin



Multi-label text classification (MLTC) assigns multiple relevant labels to a text. While deep learning models have achieved state-of-the-art results in this area, they require large amounts of labeled data, which is costly and time-consuming. Active learning helps optimize this process by selecting the most informative unlabeled samples for annotation, reducing the labeling effort. However, most existing active learning methods are designed for traditional single-label models and do not directly apply to deep multi-label models. Given the complexity of multi-label tasks and the high cost of annotations, there is a need for active learning techniques tailored to deep multi-label classification.
Active learning enables a model to request labels for the most informative unlabeled samples, reducing annotation costs. Common active learning approaches include membership query synthesis, stream-based selective sampling, and pool-based sampling, focusing on the latter in this work. Uncertainty-based sampling is often used in multi-label classification, but challenges still must be solved in applying active learning to deep multi-label models. While Bayesian deep learning methods have shown promise for uncertainty estimation, most research has focused on single-label tasks.
Researchers from the Institute of Automation, Chinese Academy of Sciences, and other institutions propose BEAL, a deep active learning method for MLTC. BEAL uses Bayesian deep learning with dropout to infer the model’s posterior predictive distribution and introduces a new expected confidence-based acquisition function to select uncertain samples. Experiments with a BERT-based MLTC model on benchmark datasets like AAPD and StackOverflow show that BEAL improves training efficiency, achieving convergence with fewer labeled samples. This method can be extended to other multi-label classification tasks and significantly reduces labeled data requirements compared to existing methods.
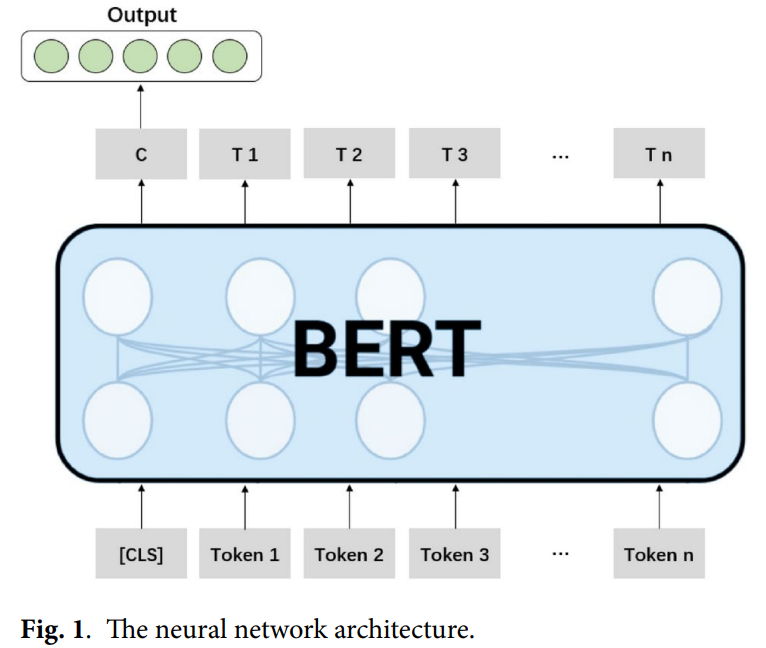
The methodology introduces a batch-mode active learning framework for deep multi-label text classification. Starting with a small labeled dataset, the framework iteratively selects unlabeled samples for annotation based on an acquisition function. This function chooses samples with the lowest expected confidence, measured by the model’s predictive uncertainty. Bayesian deep learning calculates the posterior predictive distribution using Monte Carlo dropout, approximating the model’s confidence. The acquisition function selects a batch of samples with the lowest expected confidence for labeling, improving the model’s efficiency by reducing the need for labeled data. The process continues until the model’s performance converges.
In this study, the authors evaluate the BEAL method for deep multi-label text classification using two benchmark datasets: AAPD and StackOverflow. The process is compared with several active learning strategies, including random sampling, BADGE, BALD, Core-Set, and the full-data approach. BEAL outperforms these methods by selecting the most informative samples based on posterior predictive distribution, reducing the need for labeled data. Results show that BEAL achieves the highest performance with fewer labeled samples than others, requiring only 64% of labeled samples on AAPD and 40% on StackOverflow. An ablation study highlights the advantage of using Bayesian deep learning in BEAL.
In conclusion, the study introduces BEAL, an active learning method for deep MLTC models. BEAL uses Bayesian deep learning to infer the posterior predictive distribution and defines an expected confidence-based acquisition function to select uncertain samples for training. Experimental results show that BEAL outperforms other active learning methods, enabling more efficient model training with fewer labeled samples. This is valuable in real-world applications where obtaining large-scale labeled data is difficult. Future work will explore integrating diversity-based methods to reduce further the labeled data required for effective training of MLTC models.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 55k+ ML SubReddit.
[FREE AI WEBINAR] Implementing Intelligent Document Processing with GenAI in Financial Services and Real Estate Transactions– From Framework to Production
The post BEAL: A Bayesian Deep Active Learning Method for Efficient Deep Multi-Label Text Classification appeared first on MarkTechPost.






